姜子牙-LLaMA-13B-v1.1
我们对Ziya-LLaMA-13B-v1模型进行继续优化,推出开源版本Ziya-LLaMA-13B-v1.1。通过调整微调数据的比例和采用更优的强化学习策略,本版本在问答准确性、数学能力以及安全性等方面得到了明显提升

- 模型资讯

- 模型资料
Ziya-LLaMA-13B-v1.1
- Main Page:Fengshenbang
- Github: Fengshenbang-LM
姜子牙系列模型
- Ziya-LLaMA-13B-v1.1
- Ziya-LLaMA-13B-v1
- Ziya-LLaMA-7B-Reward
- Ziya-LLaMA-13B-Pretrain-v1
- Ziya-BLIP2-14B-Visual-v1
简介 Brief Introduction
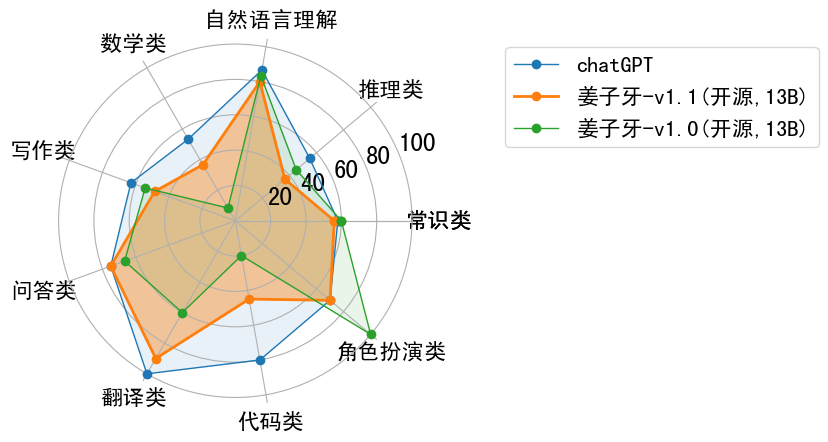
我们对Ziya-LLaMA-13B-v1模型进行继续优化,推出开源版本Ziya-LLaMA-13B-v1.1。通过调整微调数据的比例和采用更优的强化学习策略,本版本在问答准确性、数学能力以及安全性等方面得到了提升,详细能力分析如下图所示。
We have further optimized the Ziya-LLaMA-13B-v1 model and released the open-source version Ziya-LLaMA-13B-v1.1. By adjusting the proportion of fine-tuning data and adopting a better reinforcement learning strategy, this version has achieved improvements in question-answering accuracy, mathematical ability, and safety, as shown in the following figure in detail.
软件依赖
pip install torch==1.12.1 tokenizers==0.13.3 git+https://github.com/huggingface/transformers
使用 Usage
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
pipe = pipeline(task=Tasks.text_generation, model='Fengshenbang/Ziya-LLaMA-13B-v1.1', model_revision='v1.0.2', device='cuda')
query="帮我写一份去西安的旅游计划"
inputs = '<human>:' + query.strip() + '\n<bot>:'
result = pipe(inputs)
print(result)
引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的论文:
If you are using the resource for your work, please cite the our paper:
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
You can also cite our website:
欢迎引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
所属公司/组织机构