编者按:本文来自微信公众号 星海情报局(ID:junwu2333),作者:星海老局,创业邦经授权转载。
2008年,年入过亿的媒体人Jeremy Clarkson心血来潮在英国牛津附近的Chadlington查德灵顿买了1000英亩(大约6000亩)的土地,并托管给了当地的一个农民大叔。作为地主老头的Clarkson从此每年坐收数万英镑的利润。
8年后,农民大叔决定退休,Clarkson做了一个异想天开的决定:他要亲自来经营农场,并和亚马逊一起,把这个过程变成了一部火爆全球的种田纪录片:《克拉克森的农场》。
火爆的最大原因:亿万富翁灰头土脸种地年入144英镑,利润还不如直接把钱放在银行吃利息。
2021年这部纪录片上线的时候,生成式AI还没有爆火,Clarkson在冬天的农田旁边填写英国政府下发的几十页表格,却被不同作物对应的不同编码搞到焦头烂额;他异想天开养了一群羊,结果羊生病了他完全搞不明白为什么,只能到处打电话求救;他的拖拉机没有说明书,于是只能满世界找人教他每一个按钮都该怎么用……
两年后,我在去见客户的路上,又想起了这个越努力越倒霉的亿万富翁。客户也做农牧业,正在探索利用大语言模型搭建智能客服帮养殖户养猪。我突然发现,似乎让他焦头烂额的每一件事,从理论上讲,AI都可以解决。
在大模型卷生卷死的一年末尾,越来越多的人发现,单纯卷模型其实没有太大的意义,只有将大语言模型的“理论能力”真的落地到实际应用里,才有真正的意义。
大模型不是搜索引擎
大语言模型的本质是单字接龙,跟搜索引擎的逻辑天差地别——每当我告诉别人这件事的时候,通常都会得到一个极其困惑的表情。但其实这个事用案例解释起来非常好理解。
搜索引擎的逻辑是“匹配”,再简单点说就是连线游戏。比如刚刚过去的双十一,相信大家都体验过各大平台的所谓“智能客服”,这些客服的基本逻辑就是看关键词的命中,来推送给你已经预先设定好的答案。
操作流程其实可以简略地概括为:搜索——复制粘贴——给你回复。
这种连线游戏的结果其实只有两种:要么命中关键词,得到匹配的答案;要么没有命中关键词,只能告诉你“对不起,不知道”。
搜索引擎的逻辑下,智能客服的解题思路其实是“穷举法”,我把每种可能性都列一遍,然后预设好答案,当你命中了其中某种问法的时候,就把答案从资料库里复制粘贴给你。
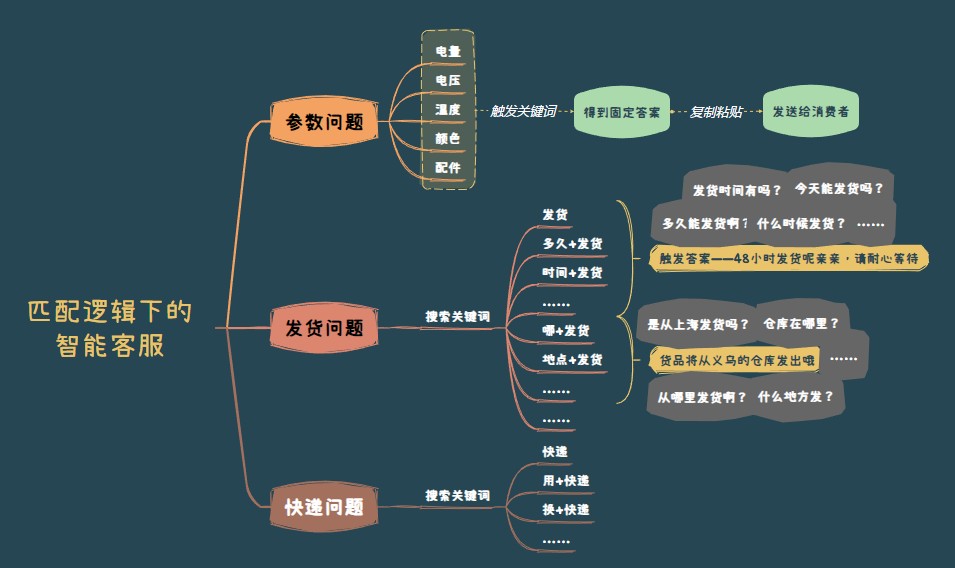
它的前提是事先付出大量人工对问法和答案进行标记,产品简单还好说,产品参数一旦复杂就会带来天量的工作任务。更可怕的是,再大的工作量都还不一定管用。
拿芯片来说,我接触过一家做芯片的专精特新小巨人公司艾为电子,旗下有近千款自主知识产权的芯片,光列在官网首页的主要产品就有8个大类,32个子类,59个产品类型,每个产品类型下面还有几个到几十个不等的产品型号,每个都显示了至少11个主要参数,这还只是展现在官网上的重点产品信息。
最可怕的是,芯片产品里的参数很多都是互相影响的。比如大家都知道芯片的使用肯定会有一个“电压”参数,一般标出来的可能都是在标准温度(比如室温)下的经典值,但实际上一个芯片可能在-40℃~85℃的温度下都可以使用,只不过零下二十度和零上80度所需要的电压值是不一样的,温度会影响实际要求。

艾为官网上的产品信息都标示了温度参数
而客户来问的时候,甚至不会跟你说明确的多少温度下行不行,他们更多是问的使用场景,比如他可能会说我把这个东西带去北极的话,它多少电压够用?或者我把这个东西丢进锅里煮的时候要多少电压?
这种问题虽然不是特别难,但是却完全没办法以穷举法的思路解决,也没办法提前标记出来。用搜索引擎式的“匹配”逻辑,显然是怎么都解决不掉这类问题的。
而生成式AI的逻辑则完全不同,同样是艾为电子这家公司,他们现在已经通过钉钉AI PaaS,调用了大模型的能力,建起了一套AI智能客服系统,解决掉了此前大量痛点,而且看上去还挺“聪明”的。我把这个实践案例列为目前国内大模型应用落地跑得最快的案例之一。
语言大模型的核心,是基于概率分布的单字接龙,它问答问题时是依据「学到的规律」,而不是搜索和匹配。
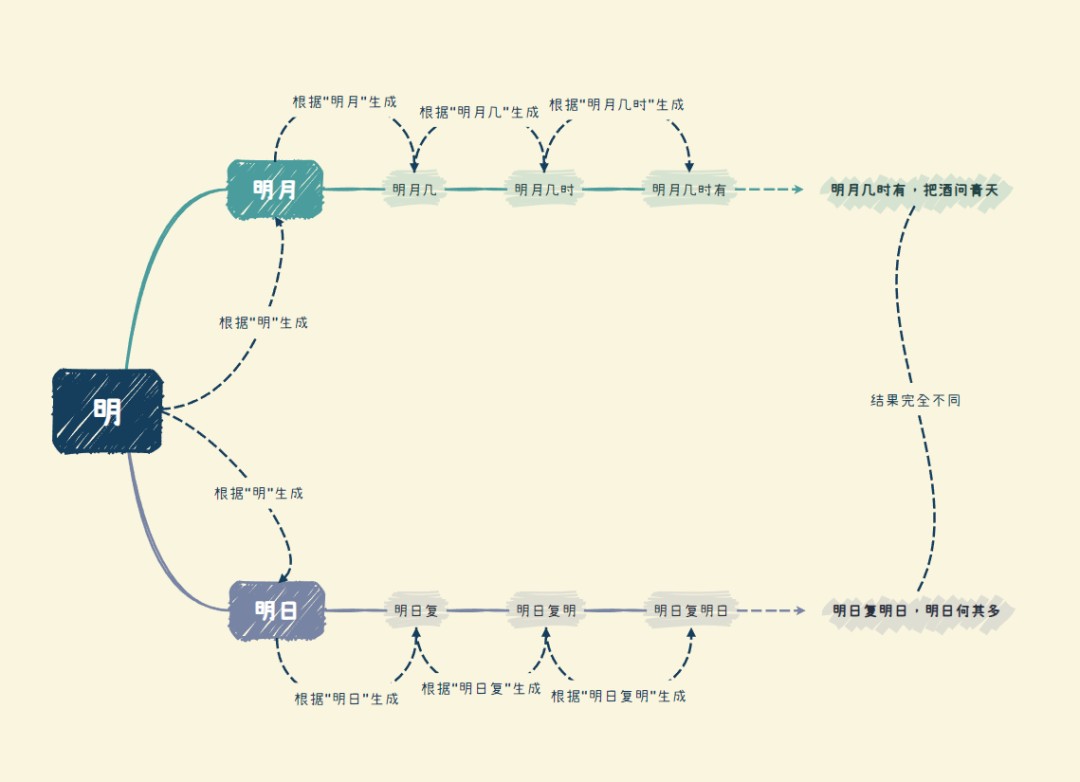
比方说,我给出一个“明”字,那它就可能生成“月”。而当我给到它“明月”这个上文时,它就有可能会生成“几”;根据“明月几”这个上文,它会生成“时”;直到最终我们得到一句“明月几时有,把酒问青天”。
但“明”字后面不是只能接“月”字,也可能接“日”,那么接下去它就很可能通过“明日”这个上文单字接龙,并最终生成一句“明日复明日,明日何其多”。
即便一开始在“明”字后面接了“月”字,“明月”后面也不一定要接“几”,也可能会是“出”,所以除了“明月几时有,把酒问青天”,你也有可能得到“明月出天山,苍茫云海间”。
那么大模型是如何在选择生成“日”还是“月”,“几”还是“出”的呢?
答案是根据概率。
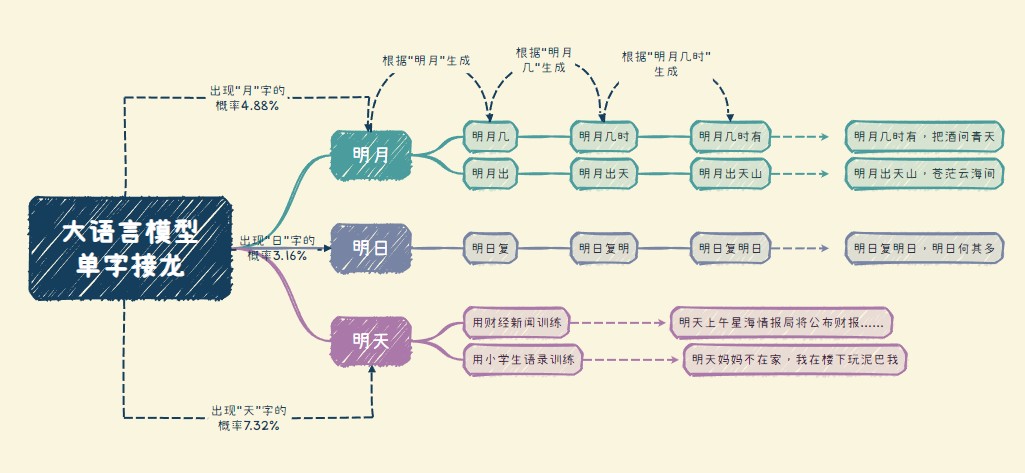
根据《现代汉语常用字表》,中文里最常用的3500个汉字能够覆盖现代主流文本99.48%的篇幅。而大语言模型所做的,就是根据你给它的学习材料,计算这3500个字分别接在“上文”后面的概率,找出概率最高的那一个字,进行单字接龙,然后不断循环,最终得出一个答案。
所以训练语料就显得格外重要,它会影响模型总结的规律。如果你给它吃唐诗宋词三百首,它会给你明月几时有,明月出天山,明月别枝惊鹊。
但如果你给它吃的全是上市公司财报和财经新闻,它可能会在“明”字后面接:“明天上午星海情报局将公布上半年财报,预计盈利五毛钱人民币”。至于我司有没有赚五毛钱人民币,咱也没教过,它也不在乎。
这就是你问AI一些事实性内容它经常给你瞎编的原因:数据库里搜索肯定是搜索不到,但你拿这玩意儿喂了它这么久,它觉得你就想要这个。
同理,如果你每天给它喂的都是小学生语录,比起“明月几时有”,它显然更可能回答你“明天妈妈不在家,我在地里玩泥巴”。
训练大模型就像教鹦鹉说话,你通过不断地喂给它资料,帮助它学习每一个字在各种情况下出现的概率。鹦鹉就会从你教它的话中提取出概率分布的通用规律,来判断每一个字后面应该接什么才最接近你想要的答案。每当接近你想要的答案,你就奖励它一口食物,换在大模型上就是给它点一个赞,这样来不断加强它的准确性。
一个已经经历过基础语言训练的大模型,比如钉钉底层的通义大模型,就像一个高三生。在其基础上加强某一方面专业语料的供给,就相当于给一个高三生选了不同的大学专业,开始让他读不同的专业书籍。
如果喂给它的都是算法、程序,它就可能长成知名的程序员;如果喂的都是农牧知识,它就能教你养猪;而艾为用产品手册和产品结构图等大量专业资料喂进去,并跟钉钉一起不断调适、训练,就得到了一个效率极高的智能客服,可以7x24小时不间断的回答你,如果想要把某个电子设备丢进锅里煮,那这个设备应该用艾为的哪款芯片。
随身携带一个王语嫣
和别人比武是什么体验?
八月份我曾经写过一篇《大逃杀里的中国AI大模型》,讲的是大语言模型卷生卷死已经卷到了后期,大家的重点正在从模型本身转换到应用之上。但问题是除了深耕AI行业的业界以外,绝大多数产业界人士对“大模型到底能帮自己做什么”还持有一种怀疑态度。
星海经常去探厂,自从大模型火了之后,我在一线经常碰到的问题就是:你觉得AI真的有用吗?那玩意儿怎么用啊?
我一般会问他:哥们,你知道王语嫣吗?
手机里有一个专有大模型的感觉,差不多就像随身携带一个王语嫣和别人比武。
王语嫣解决的最大问题是什么?
是效率。
她和随身的百科全书不一样,百科全书是知识的记载,但别人一拳打过来你还是得在浩如烟海的武林秘籍里边翻找边思考,我到底是抬左手挡还是抬右手挡比较好?但王语嫣却可以根据她高速运转的大脑和在模拟战斗界丰富的经验直接告诉你:伸左脚踹他膝盖!
AI代替了你检索信息、处理信息、并创造新的知识的过程。
当大模型可以处理上千种芯片产品相关专业信息,并依照这些专业信息直接和客户进行问答的时候,与其说这是一个智能客服,还不如说这是艾为旗下一个熟知上千本产品手册的专业员工,实际起到的作用更像是一个专家型顾问,以专业视角帮助客户了解产品,快速准确地回应客户的专业提问,并解决过程中的问题。
艾为原先的“客服”,很多都是有研发背景的技术人员,他们耗费了大量的时间在做这些并没有什么创造力的工作,即便是最专业的技术人员,也不可能把一千多款产品所有参数都记在脑子里,每次遇到问题的时候也要去重新查资料,然后思考,再进行回答。
而通过钉钉的AI能力搭建现在的AI客服系统,这些技术服务人员都被解放了出来。一方面他们可以将更多的时间花在解决一些现场更高难度的问题上,提高自己的竞争力和薪资;另一方面,企业的效率也能得到提升。
携带一个王语嫣和携带一本普通百科全书的另一个区别是:被储存起来的知识,通常是没有条理的,甚至有时可能出现重复或冲突。
四川有一家农牧食品企业叫铁骑力士,主营业务涉及饲料、牧业、食品和生物工程等,是农业产业化国家重点龙头企业,商务部第二批数字商务企业,也是全国农牧行业唯一挂牌的省级数字化转型促进中心。这家公司也在钉钉上做了基于大语言模型的生成式AI智能客服,日常回答旗下养殖户的各种奇怪问题,比如“猪拉肚子了怎么办”。
同时它还把大模型的能力接入到公司的日常运维中,做成了数字员工。他们认为文档是大模型目前最成熟的应用领域,于是把集团制度喂给AI学习,AI很快帮公司发现了问题:集团内部不同部门现行的制度居然有打架的情况,比如某个指标可能这个说是一,那个说要十,另一个又说十五才行。
这个集团有150个子公司,一年要发五十多个制度,在AI介入之前,很多行政人员也只是负责本部门的内容,对于其他部分的制度也搞不懂。AI介入之后很快把集团组织内部的很多问题检查出来,并且很快进行了科学的统一,相当于打破了组织墙和信息墙,实现了集团制度的重新梳理和体系化。
大语言模型本身是不存储数据内容的,它也不具备搜索引擎的搜索能力。它所做的不是简单的储存知识,而是学习、梳理、再处理知识,最终构成一套完整的知识体系供你调用。它从实际上改变了人类对知识创造、继承和应用的体系。钉钉上正在发生的新一轮数字化和以往截然不同。
如何做安全的魔法百科全书
大模型的终点是产业,这是已经不必过多解释的行业共识。但落入产业的过程还处于刚刚开始探索的阶段,其中最受关注的一个问题,是数据安全。
还拿艾为来说,芯片本身就是一个专业性极强的领域,敏感信息很多。要把产品的图纸、结构、参数等等全部喂给大模型,首先要考虑的就是数据安全的问题。
ChatGPT爆火时,亚马逊的公司律师就曾称,他们在ChatGPT生成的内容中发现了与公司机密“非常相似”的文本,推测是因亚马逊员工在使用ChatGPT生成代码和文本时,输入了公司内部的数据信息,而这些信息又被当成答案提供给了新的提问人。
有大量科技公司包括学校等科研机构,因此开始限制甚至禁止员工使用ChatGPT和其他各类大语言模型。欧洲各国立法限制大模型使用也是出于相同考虑。
但市场不会因为某个企业因安全禁用了大模型,而集体不用,这直接带来的后果是,很多企业和机构开始研究部署自己的大模型。但这又带来了更多的问题。
首先,成本将会达到一个很多人瞠目结舌的高度。
比如上文提到的铁骑力士就曾经使用清华的开源大模型ChatGLM尝试过本地部署。他们在这个项目花了20万买AI服务器,然后配了三个人左右来专门训练自己的AI,人力成本每年大概也要几十万。但这样一套系统虽然训练调试后效果很好,却只能支持10个人同时在线,而如果要支持100个人在线,至少要200万元左右的服务器成本。但对于企业来说,这个投入是否能够得到收益还是一个未知数。
相对来说,你就很容易理解他们为什么最后选择了钉钉来做这套系统。
首先,钉钉的模式是在大模型之上搭建了一个工程层——AI PaaS,它虽然调用底层大模型的能力,但是不会将各个企业的数据喂给底层的大模型。
以游戏来作比,就是这里产生了剧情分叉,开启了多元宇宙,A宇宙的大模型去了艾为做智能客服;B宇宙的去了铁骑力士教人养猪;C宇宙的可能在帮某公司造汽车,D宇宙的在给人盖房子。但它们互相之间不会影响,也无法获知彼此的数据。
同时,这类大模型平台,如果收费,大多数会是通过调用接口的方式来做,就是用多少给多少钱。对于企业来说,这种模式比起现场部署,自购服务器的重资产模式,要明显灵活得多,沉没成本可控,一旦效益没有达到预期,也可以迅速抽身,试错成本更低。
我在《大逃杀里的中国AI大模型》一文曾说,大模型本身不是目的,帮助生产力效率的提升,进而实现产业的发展和崛起才是目的。中国目前有超过120个大模型在卷,但真正落地应用,已经开始赋能产业的并不多。
钉钉在这方面率先做出了一些成果,其实是一件不算意外的事情。首先中国有大量中小企业,而这些公司大多数没有资金实力和技术能力自己部署大模型,借助企业服务平台和工业互联网的力量,是他们必然的选择。
其次,钉钉本身就是杀手级的企业服务平台,有很多公司本来数据就沉淀在自己的钉钉里,依托这个体系接入大模型的能力,实现企业内部AGI,是最方便的。IM和群聊又是企业办公和业务中最高频的场景,没有IM的大模型在这方面就有明显的短板,比如我利用你的大模型做了一个智能客服,但是有问题解决不掉的时候,你只能给我发短信,这就尴尬了。
而在钉钉,所有信息和数据都是可以直接打通的,有问题推送一个消息过来就好了,想建个日程也可以让AI自动完成,直接就出现在日程表里了。这种学习成本对内对外都明显更低,推广起来十分方便,不需要再额外下App或者去重新登录网页。
结语
人类自身是一个相当脆弱的物种,跑不过马,打不过熊,嗅觉不如狗,视力不如鹰,我们在生理意义上的缺陷如此明显,能够在众多高等动物中脱颖而出的,就是基于语言文字对知识的记载与传承,以及对工具的使用。
大模型很强大,但它依然是一个工具。王语嫣即便熟知所有武学,但还是不会武功,要亲身和这个世界战斗,在这个世界行走的还是人类。而工具无法取代人,只有会用工具的人,取代不会工具的人。
大模型卷生卷死,但无法落地都是空中楼阁。以钉钉为首的企业推动下,中国产业界正在逐渐实现一场关于了解大模型,应用大模型,让大模型实实在在落地到各行各业的AI变革。
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。