
编者按,本文来源量子位,作者鱼羊,创业邦经授权发布。
训练神经网络,硬件要过硬?现在谷歌提出强有力反驳。
GPU和像谷歌TPU这样的硬件加速器大大加快了神经网络的训练速度,推助AI迅速成长,在各个领域发挥超能力。
然而,硬件发展再迅速,也总有力有不逮的时候。
比如,由于芯片的架构方式,像数据预处理这样的训练pipeline早期阶段并不会受益于硬件加速器的提升。
谷歌大脑的科学家们可不希望看到算法掣肘硬件,于是他们研究出了一种名为“数据回放(Data Echoing)”的新技术。
加速神经网络训练速度,这回不靠折腾半导体。
Data Echoing的黑科技
新的加速方法的核心在于减少训练pipeline早期阶段消耗的时间。
按照经典的训练pipeline,AI系统先读取并解码输入数据,然后对数据进行混洗,应用转换扩充数据,然后再将样本收集到批处理中,迭代更新参数以减少误差。
而Data Echoing是在pipeline中插入了一个阶段,在参数更新之前重复前一阶段的输出数据,理论回收空闲算力。
如果重复数据的开销可以忽略不计,并且echoing任意侧的阶段都是并行执行的,那么数据回放完成一个上游步骤和e个下游步骤的平均时间就是: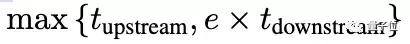
假设上游步骤花费的时间大于等于下游步骤花费的时间,你会发现附加的下游步骤是“免费”的,因为它们利用了空闲的下游容量。
data echoing缩短训练时间的关键在于上游步骤和下游步骤之间的权衡。
一方面,重复数据的价值可能会比新数据的价值低,那么data echoing就需要更多的下游SGD(随机梯度下降)更新来达到预期性能。
另一方面,data echoing中每个下游步骤仅需要1/e个上游步骤。
如果下游步骤因回放因子而增加的数量比e小,那么上游步骤的总数就会减少,总的训练时间也就减少了。
需要注意的是,有两个因素会影响在不同插入点处data echoing的表现:
在批处理前回放(echoing)
在批处理之前回放意味着数据是在样本级别而不是批处理级别重复和混洗的,这增加了临近批次不同的可能性,代价是批次内可能会有重复的样本。
在数据扩增前回放
在数据增强之前进行回放,重复数据就可能以不同的方式转换,这样一来重复数据就会更像新数据。
效果如何
研究团队对这一方法进行了实验,他们选择了两个语言模型任务,两个图像识别任务和一个对象检测任务,AI模型都是用开源数据集训练的。
实验中,“新”训练样本(训练样本从磁盘中被读取出来,就算做一个新的样本)的数目达到指定目标的时间就算作训练的时长。同时,研究人员也会调查data echoing是否减少了所需的样本数量。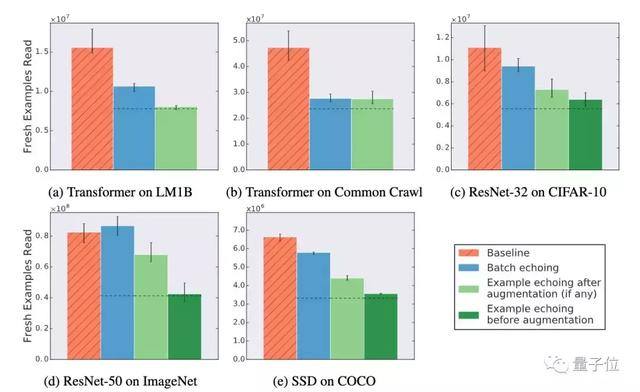
除了用ImageNet训练的ResNet-50,data echoing的效率都比基线方法效率高。并且更早地在pipeline中插入echoing,训练所需的新样本会更少。
而随着批量大小的增加,data echoing相对于基线方法的改进会更加明显。
摩尔定律的黄昏
随着摩尔定律走向终结,要依靠芯片制造工艺的突破来实现人工智能算力的提升越来越困难,虽然有硬件加速器加持,但CPU这样的通用处理器依然成为了神经网络训练速度进一步提升的拦路虎。
另辟蹊径,以算法性能来突破重围,正在成为New sexy。
论文地址:https://arxiv.org/abs/1907.05550
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。






