
编者按:本文系专栏作者投搞,作者Alter。
美国知名投资机构Mangrove Capital Partners在《2019年语音技术报告》中,给语音下了一个宏大的定义——欢迎下一代的颠覆者。
可如果把时间倒退10年,大部分人还是会把“语音交互”定义为一场豪赌,都知道赢面比较大,却迟迟不敢下注,因为概念的落地还没有一个明确的期限,当正确的路径被走通之前,永远都存在不确定性。
不过在此前的80年里,人类对语音技术的希望从未破灭,就像是在迷宫中找寻出口一般,一遍又一遍的试错,最终找到了正确的路径。
01 漫长的孩提时代
“小度小度,明天天气怎么样?”“小度小度,我想听周杰伦的歌” “小度小度,我想给爸爸打电话”,诸如这样的指令每天有几亿次发生,哪怕是牙牙学语的孩子也可以和智能音箱进行流畅的对话。
但在50年前,就职于贝尔实验室的约翰·皮尔斯却在一封公开信中为语音识别下了“死亡诊断书”:就像是把水转化为汽油、从海里提取金子、彻底治疗癌症,让机器识别语音几乎是不可能实现的事情。
彼时距离首个能够处理合成语音的机器出现已经过去30年的时间,距离发明出能够听懂从0到9语音数字的机器也过去了17个年头。这两项创造性的发明均出自贝尔实验室,但语音识别技术的缓慢进展,几乎消磨掉了所有人的耐心。
在20世纪的大部分时间里,语音识别技术就像是一场不知方向的长征,时间刻度被拉长到了10年之久:
上世纪60年代,时间规整机制、动态时间规整和音素动态跟踪三个关键技术奠定了语音识别发展的基础;
上世纪70年代,语音识别进入了快速发展的阶段,模式识别思想、动态规划算法、线性预测编码等开始应用;
上世纪80年代,语音识别开始从孤立词识别系统向大词汇量连续语音识别系统发展,基于GMM-HMM的框架成为语音识别系统的主导框架;
上世纪90年代,出现了很多产品化的语音识别系统,比如IBM的Via-vioce系统、微软的Whisper系统、英国剑桥大学的HTK系统;
但在进入21世纪后,语音识别系统的错误率依然很高,再次陷到漫长的瓶颈期。直到2006年Hiton提出用深度置信网络初始化神经网络,使得训练深层的神经网络变得容易,从而掀起了深度学习的浪潮。
只是在2009年之前70年左右的漫长岁月里,中国在语音识别技术上大多处于边缘角色,1958年中国科学院声学所利用电子管电路识别10个元音,1973年中国科学院声学所开始了计算机语音识别,然后是863计划开始开始组织语音识别技术的研究,直到百度、科大讯飞等中国企业的崛起。
02 跃进的少年时代
2010年注定是语音识别的转折点。
前一年Hinton和D.Mohamed将深度神经网络应用于语音的声学建模,在小词汇量连续语音识别数据库TIMIT上获得成功。
从2010年开始,微软的俞栋、邓力等学者首先尝试将深度学习技术引入到语音识别领域,并确立了三个维度的标准:
数据量的多少,取决于搜索量、使用量的规模;算法的优劣,顶级人才扮演者至关重要的角色;计算力的水平,关键在于FPGA等硬件的发展。
在这三个维度的比拼中,谁拥有数据上的优势,谁聚集了顶级的人才,谁掌握着强大的计算能力,多半会成为这场较量中的优胜方。于是在语音识别的“少年时代”,终于开始了跃进式的发展,刷新纪录的时间间隔被压缩到几年到几个月。
2016年语音识别的准确率达到90%,但在这年晚些时候,微软公开表示语音识别系统的词错率达到了5.9%,等同于人类速记同样一段对话的水平,时任百度首席科学家吴恩达发声称百度在2015年末即达到了同等水平;2017年6月,Google表示语音识别的准确率达到95%,而早在10个月前的时候,李彦宏就在百度世界大会上宣布了百度语音识别准确率达到97%的消息。
一个有些“奇怪”的现象,为何在语音识别领域缺少前期积累的中国,可以在极短的时间内实现从无到有,甚至有后发先至的趋势?可以找到的原因有二:
首先,传统专利池被挑战,竞争回归技术。
语音识别进入深度学习时代,并没有背负太多的专利包袱,中美玩家们有机会站在了同一起跑线上。
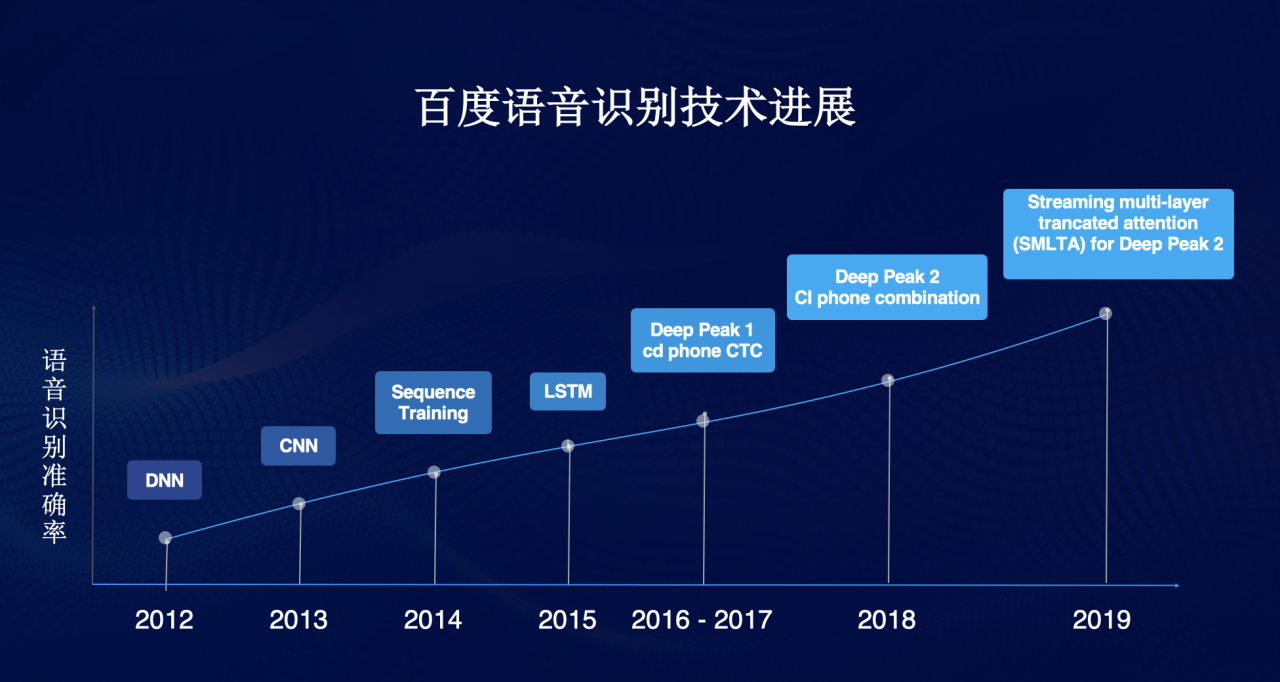
比如2013年百度的语音识别技术还主要基于mel-bank的子带CNN模型;2014年就独立发展出了Sequence Discriminative Training(区分度模型);2015年初推出基于LSTM –HMM的语音识别,年底发展出基于LSTM-CTC的端对端语音识别系统;2016年和2017年将Deep CNN模型和 LSTM、CTC结合起来,2018年推出Deep Peak 2模型,2019年又发布了流式多级的截断注意力模型……
而在不久前结束的百度AI开发者大会上,百度还推出了针对远场语音交互的鸿鹄芯片,可以实现远场阵列信号实时处理,高精度超低误报语音唤醒以及离线语音识别。
其次,语音识别进入到生态化、产业化的时代。
在Google发布了语音开放API后,对Nuance产生了致命的打击,不仅仅是Google在产品和技术上的优势,也来自于Google强大的人工智能技术生态,例如以TensorFlow为代表的深度学习引擎。
同样的逻辑,百度在2015年就开放了上百项智能语音专利,与海尔、京东、中兴通讯、中国普天等组建了智能语音知识产权产业联盟,同时PaddlePaddle、Warp-CTC、百度大脑的开放和开源,对中文语音识别有着潜移默化的影响,成为了中国语音识别领域标准的制定者。
语音识别的话语权,逐渐从大学和机构的实验室转移到了微软、Google、百度等商业巨擘手中,并最终迎来了跃进式发展的十年。或许语音技术的“少年时代”还有很长的路要走,但终究走出了漫漫黑夜,瞥见了黎明的曙光。
03 语音交互的“诱惑”
需要思考这样一个问题:为何语音识别在80年的技术长征中,出现了这样或那样质疑的声音,仍然对语音识别如此痴迷?前70年的答案可能是希望,最近10年的驱动因素则可能是庞大蛋糕的诱惑。
先来盘点一下2010年后语音识别走向应用的三个过程:
一问一答阶段:彼时语音识别在自我学习、逻辑推理方面还有很大欠缺,不能针对同一对话内容展开深入交互,比如你问天气如何,系统会自动调取天气数据,接着问明天天气如何?会调取明天的天气预报。但今天天气和明天天气之间都是各自独立的对答,不能连接贯通,也未能形成逻辑。
有问有答阶段:语音识别开始在问答的基础上有了对话的属性,对应的产品有苹果的Siri、Google Now、百度语音、微软Cortana等等,彼时仍然停留在“人机对话”,处于机器被动接受人类输入大量数据阶段,不能更深层次理解人的意思,无法实现自学习、自成长,与机器的语音交流还不能像人一样自然。
自然交互阶段:从语音识别到语音交互,不仅有问有答,人工智能还可以根据上下文逻辑和环境信息,作出个性化的决策或推荐。典型的场景就是智能音箱,亚马逊、谷歌、百度、阿里等无不开始在智能音箱领域发力,语音识别入口正逐渐撬开内容、IoT等生态,已然是AI入口之争的主战场。
不难从中看到这样的变化:刚开始的语音识别还处于造技术的阶段,可能仅仅是为了新奇炫酷的体验,但随着智能音箱、语音助手等软硬件应用的普及,解决了一个又一个棘手的痛点,语音交互开始有了成为下一代人机交互方式的可能,进而打造一个以语音为入口的全新操作系统。
可以借鉴脑学界“感官侏儒”的说法,手和舌头是人类最灵活的两个部分,从DOS系统到施乐的图形化界面再到移动设备的触控交互,无不依赖于手的交互。
而当语音技术和人工智能同时走向成熟,或许就像《2019语音技术报告》中所描述的:“语音交互扭转了以往人机交互的存在形态,用户与设备间基于语音交互的全新关系开始搭建,与之前互联网向移动互联网过渡一样,其对底层平台的全新需求也在酝酿当中。”
甚至不排除语音优先的可能,亚马逊Alexa首席科学家Rohit Prasad曾直言:“我们希望消除与客户的摩擦,最自然的方式就是通过声音。它不仅仅是一个能提供一堆结果的搜索引擎,它还会告诉你答案。”言外之意,语音技术可以帮助人们摆脱文字和屏幕的束缚,提供一种升维的用户体验。
04 巨头们的新战场
接过前辈们的衣钵,Google、百度等巨头并非没有“私心”。因为在语音交互成为人机交互主流方式的同时,也在重构现有的商业规则。正如李彦宏在《人民日报》发表的文章中所说,“作为引领此次变革的战略性技术,人工智能对世界的影响将远超以往历次工业革命。”
比如在触控交互的世界里,人们与服务的连接通过这样或那样的App,生活中也出现了社交、搜索、电商、资讯等领域的诸多超级App,但语音交互是典型的服务找人,诸如搜索、电商、社交、广告等主流的盈利路径都将被重构,乃至颠覆现有的市场格局。
一个典型的例子,不管是国内百度的小度助手,还是Google Assistant、亚马逊Alexa,早已不再满足于“语音助手”的身份,在功能上开始向语音对话、内容服务、IoT设备管理等方向演进,在场景上覆盖了家庭、汽车、酒店等等,以语音交互为切入的生态系统早已有了雏形,成为触控之外的又一个杀手级应用。
同时语音的颠覆性也逐渐浮出水面,原先想要听一首歌、看一部电影的时候,需要在手机上打开特定的App,手动输入歌曲或电影的名字,在一连串的搜索结果中找到自己需要的。语音交互的场景下,只需要发出相应的语音指令,设备就可以自动播放你想要的歌曲或视频,不仅在效率上指数级提升,也在改变音乐或视频服务方的地位,从前端走向后台的内容供应商。
截止到目前,几乎所有的互联网巨头都对语音势在必得,尤其是在炙手可热的智能音箱赛道上,国外出现了谷歌、亚马逊、苹果等巨头林立的局面,国内的百度、阿里、小米直接拿到了90%的市场份额,并且有着一家独大的趋势。
在美国,亚马逊占据了智能音箱64.6%的份额,而在国内,StrategyAnalytics、Canalys和IDC无不在报告中指出了这样的事实:去年才正式发力智能音箱的百度,早已成为世界前三、中国第一的品牌。
特别是随着语音技术的持续深入,巨头们也开始改变自己的战略路线,百度就是一个特例。
2016年就在内部形成了“夯实移动基础,决胜AI时代”的驱动战略,并确立了AIfirst的公司架构,相继打造了包括语音技术、图像技术、视频技术、NLP、知识图谱、数据智能以及深度学习等技术研线的AIG,涵盖全自动驾驶、智能辅助驾驶以及车联网业务的AIG,业务范围涉及小度助手、智能音箱等软硬件语音技术的SLG。
如此,语音技术不仅为人机交互提供了新的可能,也在一定程度上成了巨头从互联网跨向AI赛道的“引路人”。
如果以2019年作为新起点的话,语音识别已经从双翼飞机时代进入喷气式飞机时代,下一步的目标无疑就是成为火箭级的产品。幸运的是,在这场决定着未来科技生态的战场上,中国的玩家不再缺席,而是从跟随者变成了领导者。
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。


