
鄢贵海在中国计算机学会芯片大会上做DPU主题报告
在DPU概念诞生之初,人们争论它“应如何定义”,但后来发现,只有定义,还远不能说明 DPU能做什么、有什么作用、如何与现有系统更好地协同。本文将讨论DPU发展中的四个关键问题:DPU是什么?DPU可以标准化吗?DPU产业化面临哪些挑战?以及是否有“中国方案”?一些问题目前还很难给出确切的答案,但抛砖引玉,希望引起大家的关注。
一、DPU是什么?
DPU是新进发展起来的一种专用处理器,但是对于DPU的释意却不如之前的一些处理器一样容易做到“不言自明”。比如GPU,大家听名称就知道是什么,名称就是定义了。类似的还有数字信号处理器DSP,深度学习处理器NPU等。其实,CPU也是一个释义并不清晰的概念,对于“中央”是什么含义,大概在50年前也没有太多争论。但是CPU需要干什么,在系统中的角色是什么,确实比较清楚的——这其实才是首要的问题。相较而言,所谓的“定义”反而不是那么重要。简言之,DPU的参考结构是什么、能处理什么类型的负载,怎么集成到现有的计算体系中去才是DPU研发要解决的关键问题。
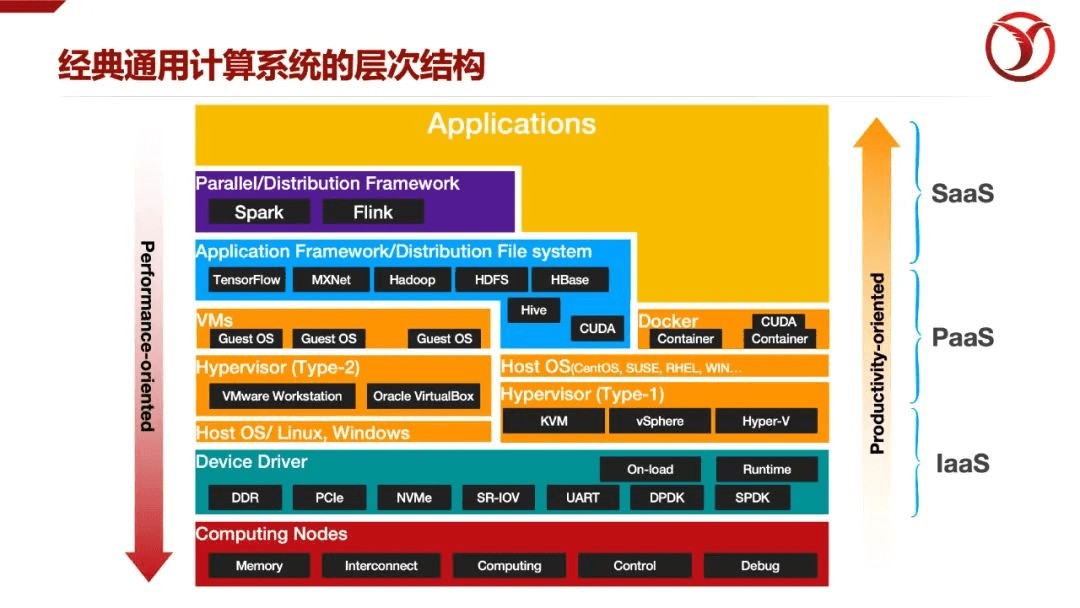
DPU是面向基础设施层的数据处理单元。鉴于此,Intel也把自己的DPU称之为“IPU”。那么所谓的基础设施层,是有别于应用层而言的,是为了给予应用提供物理或虚拟化资源,甚至提供基础服务的逻辑层。其实这个概念很好理解,从我们先有的计算系统的宏观逻辑层次来看,本身就被人为的分为基础设施层(IaaS),平台层(PaaS),软件层(SaaS),最上层就是应用层。如果微观来看,就会更清晰了。基础层主要包括与硬件资源交互、抽象硬件功能的组件,包括的网络,存储,服务器等。从优化技术的侧重点来看,越基础层的组件越倾向于以性能优先为导向,存在更多的“机器依赖(Machine-dependent)”,越上层的优化越以生产效率为导向,通过层层封装,屏蔽底层差异,对用户透明。

DPU是面向基础设施层的数据处理单元
那么,难道现有的数据中心的CPU、GPU、以及路由器、交换机,不能继续作为“面向基础设施层的数据处理单元”吗?在计算系统的研究,很大程度上是“优化”的研究。现有的基础设施不是不能,而是不够“优化”。如果没有新技术的发明和引入,最终需求和供给之间的矛盾就会越来越突出。
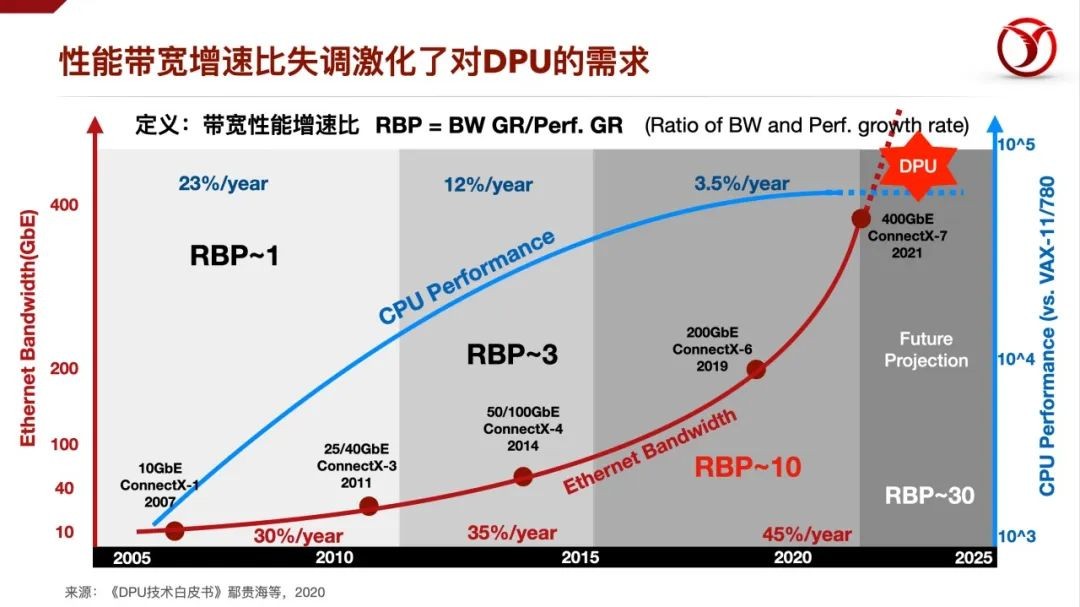
DPU的出现首先要解决的就是网络数据包处理的问题。传统来看,2层网络的数据帧是网卡来处理,由CPU上运行的OS中的内核协议栈来来处理网络数据包的收发问题。这个开销在网络带宽比较低的时候,不是大问题,甚至中断开销都可以接受。但是,随着核心网、汇聚网朝着100G、200G发展,接入网也达到50G、100G时,CPU就无法在提供足够的算力来处理数据包了。我们发现了一个现象,称之为“性能带宽增速比失调”,简单理解就是CPU性能由于摩尔定律的放缓,性能增速也随之放缓,但是网络带宽的增速来自于应用的丰富,数据中心规模的扩大,数字化进展的驱动,所以增速反而更加的迅速,这就进一步加剧了服务器节点上CPU的计算负担。
另外一个例子是在云计算场景下的一个核心应用,虚拟机之间的数据转发问题,即OVS。通常而言,20个VM需要消耗的算力,如果用Xeon的多核CPU来处理,大概需要5个核的算力——这确实还是比较大的开销。
此外,目前的系统结构,其实并不是为处理网络数据而生的,而是为了更高效的管理本地资源,支持多用户、多任务并行,本地安全,适当并发,所以必须划分不同特权指令的执行和访问权限,采用复杂的中断机制。这些机制对于高带宽网络、随机访问、高并发度收发的场景效率并不高。所以现有技术开辟了用户态访问机制,直接绕过操作系统内核态,用轮询替代中断来处理IO操作。这些在现在体系基础上的“修修补补”的权宜之计,本质上是经典技术在新场景下的不适应。
为了更好的理解DPU在系统中的角色,可以借助一种经典的计算系统模型,把系统按照逻辑功能划分为三个部分:1)数据平面(Data Plane),定义为用于数据包解析和处理的数据通路,代表计算与数据密集的功能部分;2)控制平面(Control Plane),定义是为输入输出数据流提供和配置数据平面的算法集合,代表资源调度、系统配置、链路建立等控制密集的功能部分。此外,业界通常还增加了第三个层面,即3)管理平面(Mgmt. Plane),代表系统监控,故障隔离,在线修复等周期性或偶发性的部分应用。其实这也是在“软件定义网络SDN”方法学下的一种划分。如果把一个城市的路网基础设施比做SDN,那么众横交错的道路就是其“数据平面”,其路网密度和宽度决定了路网的流量上限;所有的交通灯及其控制系统就是其“控制平面”,其控制算法优劣、部署位置的合理程度决定了交通流量实际容量;各种测速点、流量监控、临时交通管制、事故拥塞疏导等就是其“管理平面”。有了这套基础设施,各类用户就可以应用各种车辆(相当于用户的应用程序)来开展运输服务了。
对于不同平面,对可并行度、性能、灵活性、可靠性等属性通常都有比较大的不同。对于数据平面,突出的诉求就是性能,通过开发数据级、线程级,任务级并行度,高度定制化专用计算单元,一切优化设计都是性能导向。而对于控制平面,主要诉求是通用灵活,便于作为控制数据平面的抓手,把使用权交给用户。管理平面的功能主要是安全、可靠、易用,便于系统状态监控、维护,方便支持自动化运维等机制的实施。
为什么要从这三个平面来入手来看待DPU在系统中的角色呢?因为这三个逻辑平面反映了DPU设计过程中需要关注的内容。有人把DPU单纯的理解为给CPU“减负”,把DPU作为一个网卡的“变种”,只是一个被动设备,把DPU视为一个单纯的算法硬件化的载体,以“头脑简单,四肢发达”的形象示人,属于单纯追求强数据平面,弱控制面的设计。比较典型的如数据加密,图像转码专用卡,AI加速卡等,这是异构计算的“1.0时代”。

如果我们重新审视一下系统功能的载体分布情况,就会看到DPU其实越来越不像是一个单纯的加速器,而是与CPU全方位配合的一个关键组件。传统的经典的计算系统,我们称之为类型I(Type-I)是主机端负责所有的管理、控制、数据面的功能;异构计算的发展最先牵住的“牛鼻子”就是数据密集、计算密集的算法加速,所以主要卸载的就是数据面的计算负载,但是控制、管理都很少涉及,我们称之为类型II(Type-II)。一个典型的表征就是从Host端只能发现这个计算设备,但是对于设备的状态,启动、关闭、任务分配等都比较不方便。随着智能网卡等形态的产品出现,在设备端除了数据面的优势得以强化外,出现了完整的控制面功能,我们称之为类型III(Type- III)。例如ARM的控制器,运行了轻量级的操作系统用于管理板卡上的资源;这也是目前比较常见的类型。还有最后一类,Type-IV,是DPU承担所有数据面、控制面、管理面的功能,而HOST侧反而不那么重要的,这被认为是DPU的终极形态,即完全以DPU为中心来构建计算系统。前不久阿里云公布的CIPU(Could Infrastrucutre Procesing Unit)宣称替代CPU成为新一代云计算核心硬件,可以说是把DPU推向了舞台的中心,虽然也有很多争议,但这也许正是DPU发展的方向。
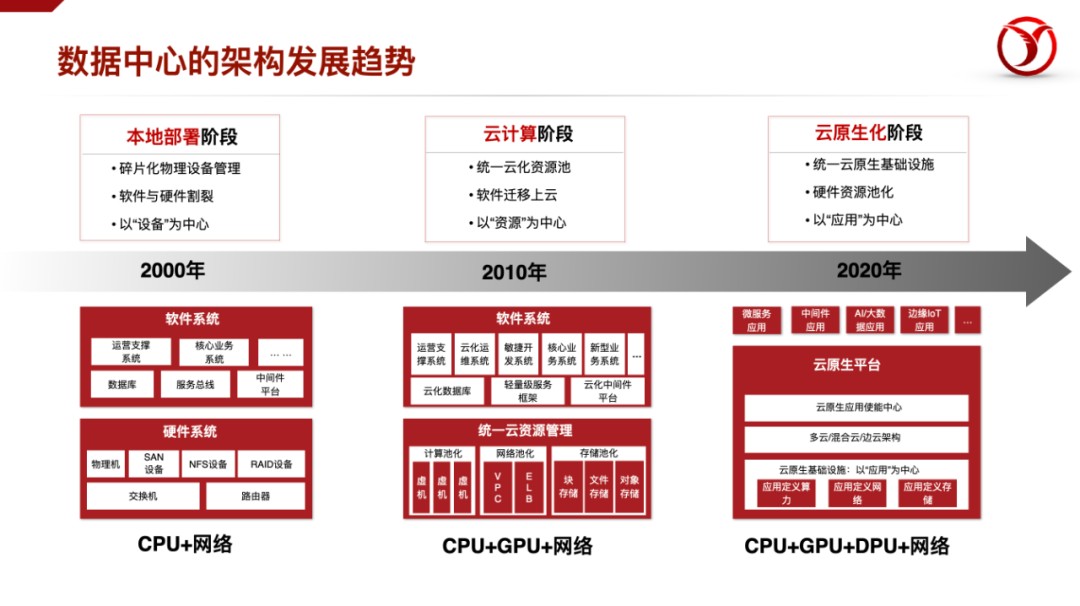
我们再来看看DPU具体能干什么。我们把DPU发挥作用的场景分为四个方向,分别为网络、存储、计算和安全,这四个方向其实是有依赖关系的,在这个图中,具有相邻关系的部分代表了一定的依赖;计算的部分涉及到的PaaS的内容偏多,网络的部分偏IaaS层,存储、安全在IaaS和PaaS层都比较多。覆盖这个分类图中越多的场景就是目前DPU各厂商努力的目标。
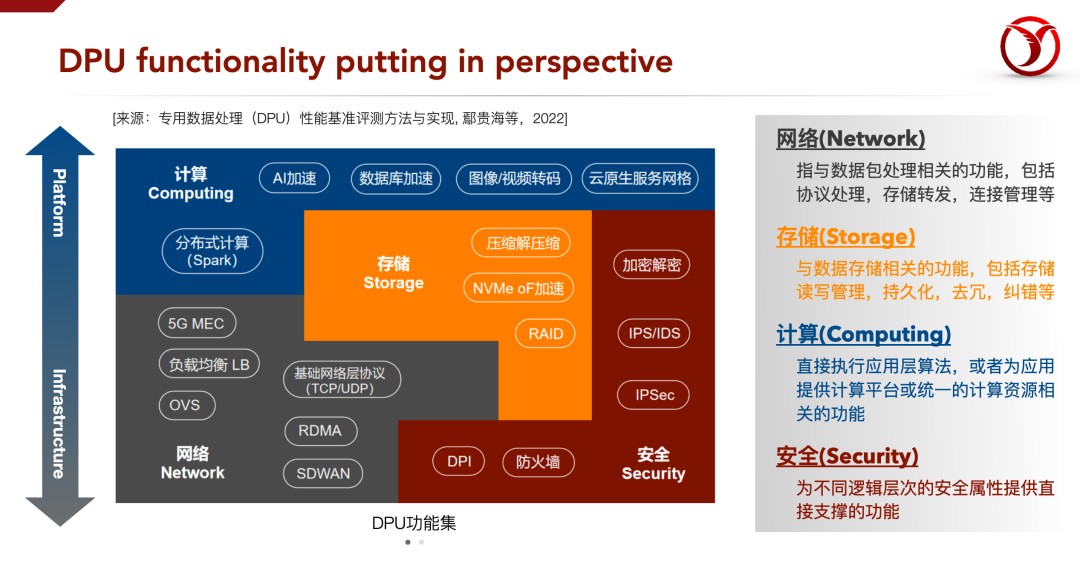
DPU功能场景
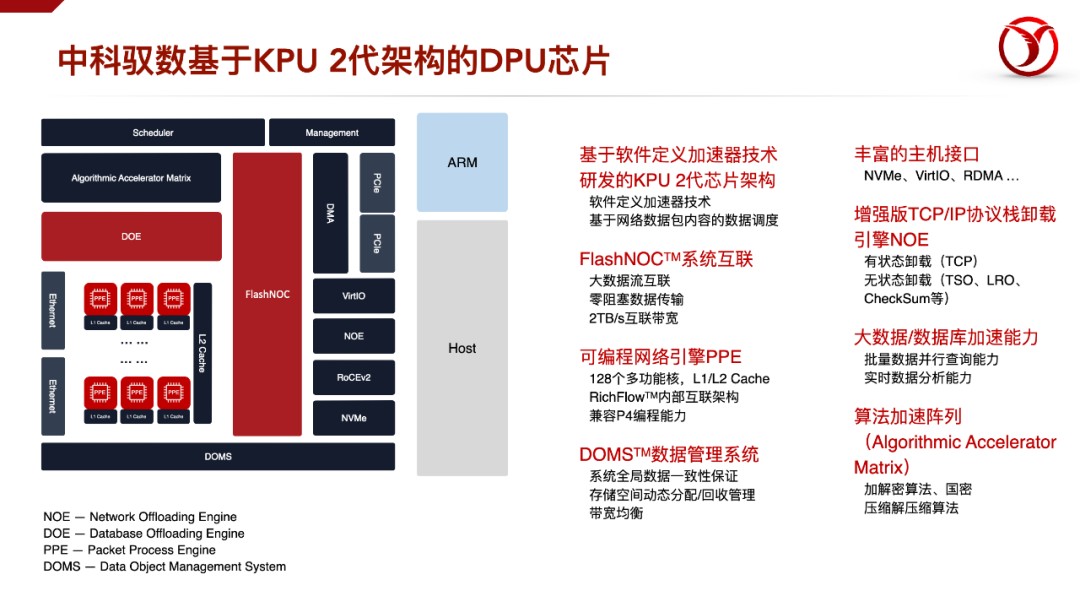
为了实现这个功能,我们可以通过我们研发的第二代架构的DPU产品结构来体现。在这个架构中,有几个比较创新的功能单元,比如NOE,是传统TOE的升级版;DOE,是专门用于做数据查询加速,还有DOMS,是一种高效的管理片上缓存数据的结构。其它的创新的结构还包括,FlashNOC的片上互联技术,还有多种面向特定IO的DMA的单元等等。
最后,如果说DPU发展最大的驱动力,其实还是来自需求侧。数据中心的架构发展趋势已经从20年前的本地部署集群,到十年前的云化资源,再到目前的云原生阶段。基础设施层变得越来越厚重,向下越来越强化硬件资源的池化,向上是“XaaS”,即“一切皆可服务化”。K8S等系统成为了新的“操作系统”,服务网格成为了新的网络化应用开发基础,DevOps开发运维一体化……在“生产率”得到提升的同时,也直接催生了算力的需求,特别是IaaS和PaaS层的算力需求——这也是DPU的主战场。
二、DPU可以标准化吗?
在回答DPU是否可以标准化之前,需要明确标准化的确切含义是什么,以及为什么要标准化。我认为,DPU的标准化涉及两个方面:DPU的架构是否可以标准化,这影响到DPU的研发成本问题;DPU的应用是否可以标准化,这影响DPU的应用生态的问题。
现在广泛存在一种认识的误区:笼统的认为DPU是一种专用处理器,既然是“专用”,那么就不可避免的采用“定制化”才能实现,一旦“定制化”,那么“标准化”也就无从谈起了,从而得到了一个武断的结论:DPU没有产业化价值!
其实专用化、定制化、标准化这三个概念,并没有直接的因果关系。
专用化强调的是应用场景,是否值的专用化,取决于需求的的刚性。定制化是技术实现的路径选择,经常是创新和核心技术的“发源地”。标准化是为了降低边际成本,通常通过建立或融入产业生态、创造规模效益,实现创新技术的价值变现。
比如,GPU无疑是一种“专用”处理器,因为人们对图形图像这种信息交互方式是绝对的刚需;GPU中通过定制化来实现光栅操作处理器(ROP)、纹理处理器(TPC)等高度定制化的功能单元,还有超大规模的数据集同步并行处理技术,都是面向像素级海量数据处理的定制化技术;最终,通过OpenGL,DirectX等图形操作API,CUDA的通用编程框架来做标准化。所以,“专用”并不比“通用”低人一等,“定制化”甚至是解决一些应用刚需必须采用的技术选择。
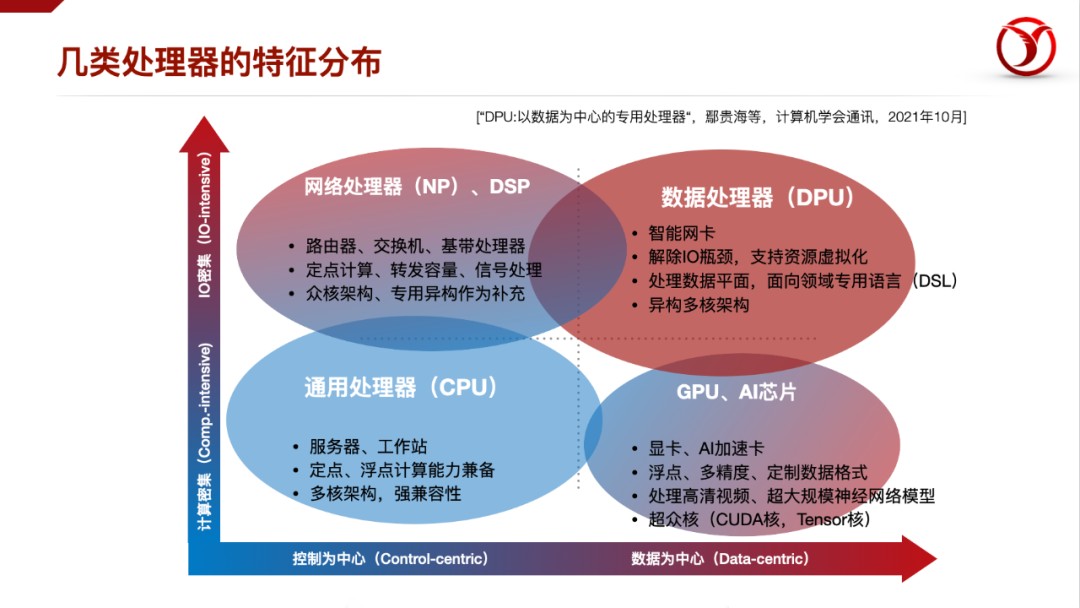
我们去年在中国计算机学会通讯上发表了一篇文章《DPU:以数据为中心的专用处理器》,其中有一个图,反映的是目前几类处理器的特征分布。从功能导向划分为计算密集 vs. IO密集,从结构设计划分为控制为中心和数据为中心;从中我们可以看到,目前DPU所处的分布区域,确实还有一定的空白。简单的演绎一下,在其它三个区域都有很好的产业化格局的时候,DPU所属的区域应该也没有道理不能产业化。

我们团队在DPU标准化工作上也作出过一点贡献。首先是组织编写了行业第一本DPU技术白皮书,这本白皮书比较全面的刻画了DPU的功能集,以及DPU的应用场景,并且给出了一个比较通用的DPU设计的参考模型。今年在过往的基础上,我们又组织编写了第二部技术白皮书,但关注的重点从DPU参考设计迁移到了DPU的性能评测方法,作为后续细分应用设计基准测试程序的参考。
我认为,DPU标准化是一个过程,而不是目的。标准化的进程很大程度与市场化程度相互作用。因此,标准化的目的是市场化,而市场化的进展也将反过来促进标准化的工作。
三、DPU产业化面临的挑战
DPU主要在基础层和平台层发挥作用,这决定了现阶段DPU的优化主要是性能导向。这其实一块特别硬的骨头。现在有些DPU的设计,过于依赖通用核的使用,尽管灵活性得到了保证,但是性能往往上不去,根本就不可能有客户买单。性能好,灵活性差,客户还会试一试;反之,是一点机会都没有的。
这里我将介绍一个大家更有切身体会的挑战——产品适配。DPU需要适配不同的CPU平台、不同的操作系统。“适配”说起来容易,做起来难,面临工作量“指数爆炸”的适配困境。例如,驭数DPU中的NOE功能是DPU行业内低延迟性能最好,在X86上的TCP和UDP的1/2 RTT回环时延可以达到1.2us甚至更低。做到如此极致,除了硬件卸载之外,也需要 YUSUR HADOS 的InstantA™ NOE SDK 针对不同CPU架构做深度优化。因此,我们在适配鲲鹏CPU + OpenEuler 操作系统时,需要解决和优化不少ARM架构和X86架构的差异化问题,例如ARM架构上的指令读写乱序的问题,最终做到了在鲲鹏CPU上TCP和UDP的1/2 RTT达到1.6us的业界突出的低时延性能。然而,当我们以为可以轻易的去适配“鲲鹏CPU + 麒麟操作系统”时,又出现了不少新的问题,例如需要解决麒麟中断处理差异,并且需要新一轮的性能优化。
鉴于此,我们提出了一套自动化多生态环境的编译、发布、测试系统平台(ADIP),把适配工作系统的分解为两条四个阶段的流水线,分别针对Host侧的软件适配和DPU侧的软件适配。这个开发集成平台已经支持了驭数的DPU在多个国产CPU和OS的适配工作,目前还在快速的完善过程中。虽然目前我们的ADIP流程自动化程度还有待提高,但是对于流程阶段的划分,已经可以非常高效的指导过百人的工程师团队来协作开发。
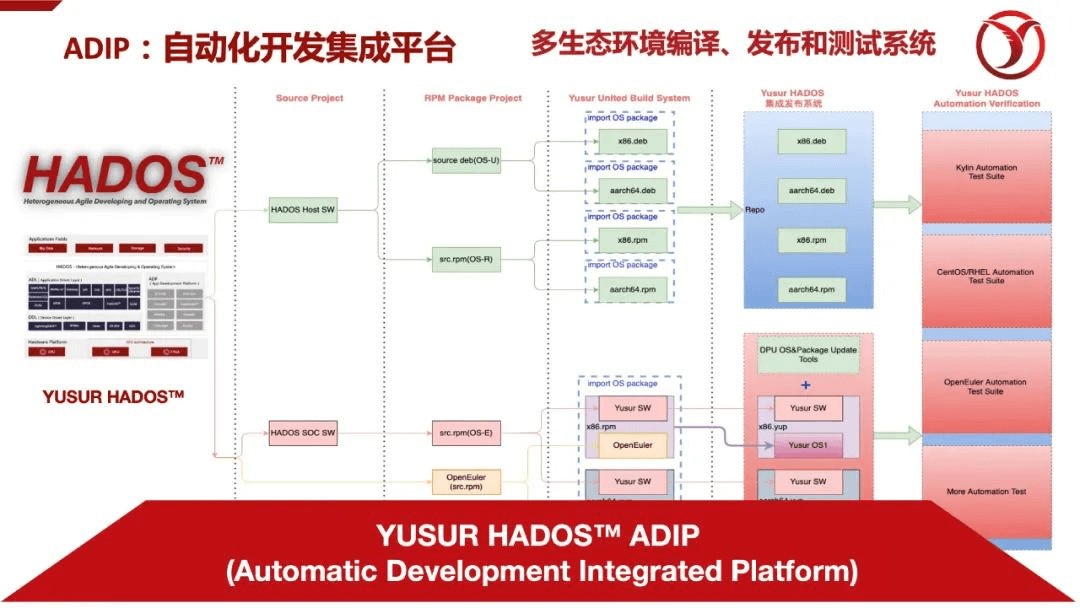
自动化多生态环境的编译、发布、测试系统平台:HADOS ADIP
以上的内容只表述了我们在开发DPU过程中的一个较大的挑战,并且分享了我们的在应对这个挑战时提出的工程化解决方案。其实,DPU还面临一些其它的挑战,一些是属于目前国内集成电路设计行业面临的共性问题,比如芯片制造的供应链问题,高水平研发人员短缺问题等等;也有DPU这个赛道的特性挑战,比如需求比较多样化,存在需求多样化与DPU设计功能出现失配(Mismatch),DPU的软件生态不够成熟等问题,虽“道阻且长”,但“行则将至”!
四、DPU的发展是否有“中国方案”?
DPU的发展是否有适合我们自己的道路或“中国方案”?这也是我们一直在思考,但尚无定论的问题。虽然DPU不分“国界”,但是DPU的产业化可能还是要找到适合我国国情的途径。
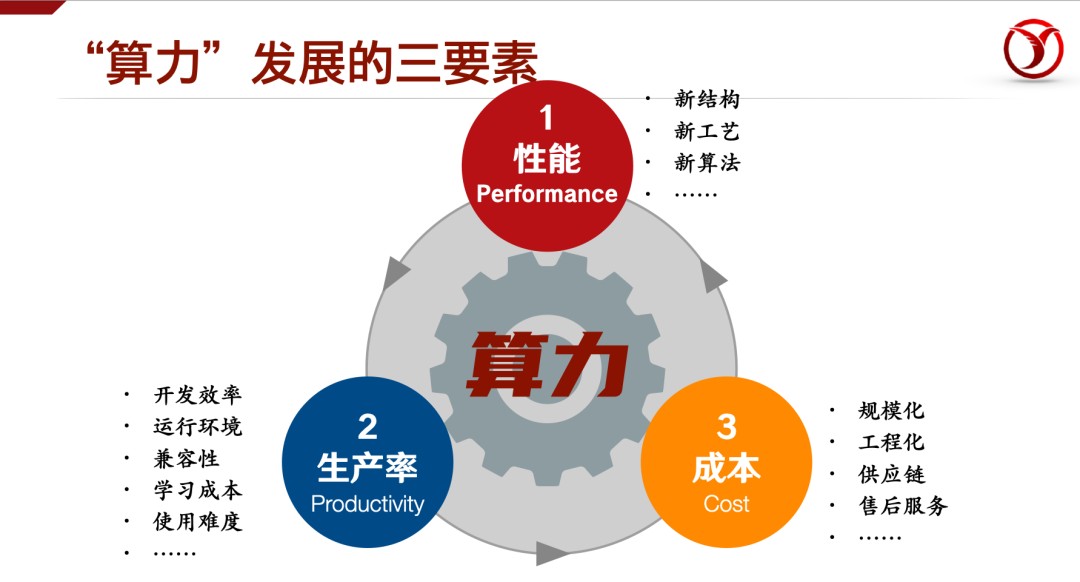
在计算系统发展的历程中,大体有三个重要的因素决定了一类产品/技术的是否能取得商业化的成功。第一就是“性能”,取决于创新结构、算法的发明,创新技术、工艺的采用等。第二就是“生产率”,与开发效率,系统与现有系统的兼容性,学习成本等因素有关。第三是“成本”,涉及到规模效应,工程化水平,供应链,以及服务成本等。
首先,DPU的性能问题一方面是设计问题,DPU的结构是不是优秀,功能是不是完善等;另一方面的问题是DPU芯片生产制造的的问题。从我们DPU设计的功能和指标上来看,我们自研的DPU和目前已经公布的一些DPU的产品相比可以说不落下风,甚至在一些单项指标上还有突出,比如时延。但是,我们的优势是局部技术上的优势,NVIDIA,Marvell的产品都有借鉴前代相关产品的功能模块,架构更加的成熟,而且已经采用了更加先进(如7nm)的工艺,从综合的产品力上来看,客观说还是有一定优势。因此,现在DPU得整体格局还是典型的“西强东弱”。
但是,中国目前算力需求是全球最强劲的。服务器的需求增速是全球第一,国家层面还有“新基建”中的“算力基础设施”的宏大布局、今年2月份启动的“东数西算”战略布局、运营商开始广泛投入的“算力网络”的建设等等。这不仅为DPU的发展提供了机遇,还给整个信息技术、计算技术的发展都提供了新的机遇。中国人擅长“摸着石头过河”,我们坚信、甚至笃信,更期待与全行业的同仁,通力协作,探索出一套“中国方案”,引领DPU这样一个新技术的发展。






