编者按:本文来自微信公众号洞见新研社(ID:DJXYS-0309),作者 | 辰纹,创业邦经授权转载。
“面对AI时代,所有产品都值得用大模型重做一次。”
这是阿里巴巴集团董事会主席兼CEO、阿里云智能集团CEO张勇在2023阿里云峰会上对AIGC(生成式AI)进化的判断,在这背后则是由ChatGPT为起始点,而引发的大模型“涌现”。
其中,既包括正在中国大陆上发生的“百模大战”,科技大厂、创业公司乃至科研机构在过去的1个月时间内争先恐后的推出或宣布即将推出自己的大模型,也包括模型在突破某个规模时,出现了意想不到的能力。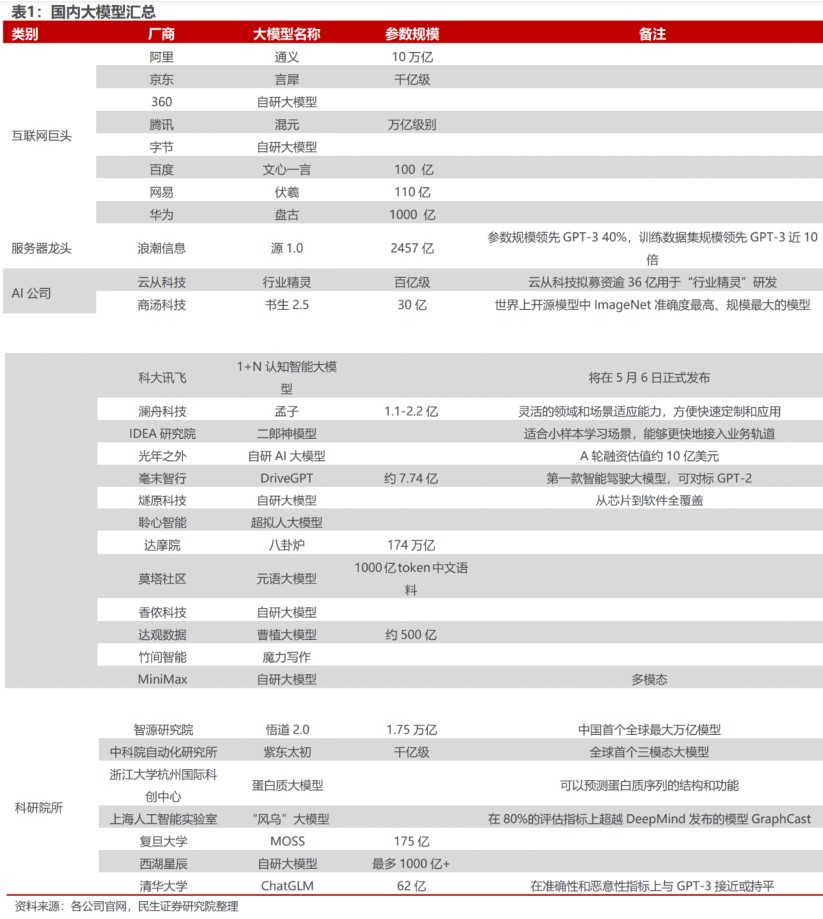
图源:民生证券研究院
打响“百模大战”第一枪的是百度文心一言,随后华为盘古、360智脑、商汤日日新、阿里通义千问、京东灵犀、昆仑万维天工等大模型先后登场,后续还有腾讯混元、科大讯飞星火等大模型排队等着上线。
与此同时,美团联合创始人王慧文、搜狗创始人王小川、出门问问创始人李志飞等科技大佬重出江湖,并且带动了一批资金,开始了大模型方向的再创业。
拨开行业竞争中真假难辨的迷雾,在张勇的语境中,大模型要用怎样的方式来再造AI,对于每个参与者来说,如何才能拿到通向大模型时代的船票呢?
由价值驱动的“百模大战”
互联网是有记忆的,从“蔚小理”带起过的新造车大战,到滴滴快的带起过的网约车大战,从摩拜和ofo带起过的共享单车大战,再到如今由ChatGPT带起的“百模大战”,牵引着玩家扎堆入局的逻辑都是由价值驱动的FOMA心理。
“FOMA”是“Fear of Missing Out(错过恐惧)”的缩写,在营销领域特指一种营销策略,即通过制造“紧迫感”或“错过”的感觉,来促使人们参与某件事情。
大模型竞争中,参与者大多害怕错过行业起势的时间窗口,抱着“我可以不强,但不能没有”的心态上车,特别是由于包括GPT 3.5在内的大模型技术都已开源,进入门槛的障碍基本被扫平,更是吸引了大量的创业公司入局,抢着与科技大厂同时起跑。
当然,更大的内驱力还是来自于大模型的价值。
首先是来自资本市场的热炒,今年2月初时,东方财富上的“ChatGPT”板块还只有29只股票,到4月份就已经攀升到60多家。
随便点几个受益公司,360受AI、信创、数据安全和ChatGPT等概念持续轮动的影响,今年以来股价上涨超过150%,昆仑万维则从AIGC+游戏进一步拓展到“天工”3.5的发布,当前市值也较年初上涨超过260%。
更加夸张的是,华为盘古大模型4月8日发布前后,带动常山北明、川大智胜、拓维信息、麒麟安信等产业链公司股价集体上涨。此外像AI标签属性较强的科大讯飞、商汤科技在公布大模型相关业务布局后,今年股价也都有不错的表现。
东方证券就表示,ChatGPT题材是超越元宇宙、虚拟现实的大风口,资本市场今年可能会反复炒作。
大模型题材在炒作的过程中,不排除个别公司确实有投机心理存在,但对于科技大厂而言,更看中大模型对自身业务推动的价值。
比如,字节跳动无论是今日头条还是抖音,内容分发在其业务布局中处于绝对核心,其内容平台的属性同时又有内容生成的需求,这与大模型主要应用的匹配度极高。
一方面能够降低创作门槛,吸引更多的创作者加入平台,另一方面,内容分发的体验能够得到持续提升,字节跳动是不可能对大模型视而不见的。
阿里在发布通义千问时,张勇就表示,包括天猫、钉钉、高德地图、淘宝、优酷、盒马等在内的所有产品都要接入大模型,进行全面改造。
以最先接入通义千问的钉钉为例,在钉钉文档中,可借助通义千问自动配图、创作文章、撰写邮件、生成方案;在会议中,可以完成记录、总结、生产待办事项;甚至还能帮助总结未读群聊信息中的要点......
这些肉眼可见的进化,让钉钉进一步加深了在协同办公场景竞争的护城河。
从云计算业务的角度,BAT、华为、字节跳动这种体量的科技巨头算力资源是现成的,跟进训练自己的大模型顺理成章,如果大模型后续成长走在行业前列,在一定程度上也能对云计算业务造成正向推动,实现双赢。
微软为OpenAI大模型训练提供云服务的成功就在眼前,贴上全世界第一个训出GPT-4云平台的标签,或多或少会加深Azure在客户心中的印象,在与AWS 的拔河拉锯中为自己又争取了些许优势。
大模型竞逐,产业融合是评判标尺
回到大模型竞争的现实,如何才能在“百模大战”中胜出?
目前跑在前面的科技大厂给出的统一答案是与产业的融合,谁的速度更快,谁的成本更低,谁的竞争就更有优势。
事实上,在大模型“涌现”之前,AI一直在探索与产业的融合,特别是像计算机视觉、语音识别、自然语言识别这类识别型AI技术,普遍采用小模型来解决一些行业中的问题,像流水线上的工业质检、交通管理中的违章识别等都是AI识别的典型能力。
这些AI在产业中有落地,但渗透的速度很慢,很大一个原因就是,小模型确实能够很好的完成指定任务,但缺点也同样明显,一个AI只能解决一个问题。
闯红灯、超速、逆行等都是交通违章,若要识别这三种违章行为,则需要对这三个场景进行三次训练,由于不具备通用性,小模型的应用范围被限定在一个很小的空间内,同时落地成本也居高不下。这也是国内AI企业一直亏钱,财报业绩长期赤字的原因所在。
大模型的出现,给AI有了一次再造的机会,其方式就是用更快的速度融入到更广阔的产业土壤之中。
阿里宣布旗下所有产品都要接入通义千问的同时,也面向企业广泛邀请参与测试,在发布会当天,阿里云就宣布将与OPPO安第斯智能云联合打造OPPO大模型基础设施,基于通义千问完成大模型的持续学习、精调及前端提示工程,未来建设服务于其海量终端用户的AI服务。
同时,中兴通讯、吉利汽车、智己汽车、奇瑞新能源、毫末智行、太古可口可乐、波司登、掌阅科技等多家企业也表示,将与阿里云在大模型相关场景展开技术合作的探索和共创。
在通义千问之前,百度的文心一言也是将B端“生态圈”作为宣传和业务重点,华为云盘古大模型则提出了“AI for Industries”理念。
曾有机构对BAT和华为大模型的核心差异做过总结:
百度:文心大模型涵盖基础大模型、任务大模型、行业大模型的三级体系,打造大模型总量约40个,产业应用覆盖了电力、燃气、金融、航天等行业。
腾讯:大模型产业化应用方向主要为腾讯自身生态的降本增效服务,其中广告类应用表现出色。
阿里:M6大模型基于阿里云、达摩院打造的硬件优势,可将大模型所需算力压缩到极致;另外其底层技术优势还有利于构建AI的统一底层。
华为:训练出业界首个2000亿参数以中文为核心的预训练生成语言模型。目前发布了盘古气象大模型、盘古矿山大模型、盘古OCR大模型三项较为重磅的行业大模型。
很显然,各家的特点都很鲜明,呈白花齐放之势,但万变不离其宗,产业融合是唯一共识。
事实上,在大模型的影响下,有些行业已经开始发生变化。
4月12日,蓝色光标发布邮件,决定无期限全面停止创意设计、方案撰写、文案撰写、短期雇员四类相关外包支出。此前,蓝色光标曾宣布将接入百度文心一言的能力。
更早之前,心动游戏CEO黄一孟发文说,已有游戏团队把原画外包和翻译外包团队砍掉,当人类被替换,大模型已经开始对行业产生实际影响了。
云计算的现在与大模型的未来
如今,大模型的竞争混沌初开,创业公司与科技巨头同台竞争,市场的最终走向将会如何?参照云计算的发展过程,我们或许已经找到答案。
众所周知,云计算市场在海外有AWS(亚马逊)、Azure(微软)和GCP(Google)三巨头,在国内则有BAT和华为,之所以是科技巨头成为云计算的绝对主角,主要在于云计算的特点,需要达到一定的规模才能产生边际效应,而在此之前,需要投入大量资源进行基础设施建设。
阿里云直到成立13年后,才在2022财年首次实现年度盈利,在其背后是遍布全球的上百个数据中心与超200万台服务器构建的云服务基础设施体系。
与云计算类似,大模型也需要耗费大量的算力资源与海量的数据成本,曾有机构估算,OpenAI训练GPT-3的成本为几百万到千万美元;训练GPT-4时,调用了上万片英伟达A100显卡,耗费的成本大约为数千万至一亿美元。
随着GPT的迭代,其训练花费将成指数级增长,有传闻,百度在训练文心一言时,调用了几乎所有的A100显卡,由此可见,大模型终究也将是少数人的游戏。
出门问问创始人李志飞在接受媒体采访时,也表达过通用AI大模型有时间窗口的观点,“人才壁垒、时间壁垒、数据壁垒、资金壁垒一旦建立起来,小的团队就没有戏了。”
李彦宏说,“重新做一个ChatGPT没有多大意义,基于语言大模型开发应用机会很大,但没有必要再重新发明一遍轮子”,表达的也是同样一个意思。
话已经说到这个份上了,大模型创业还有机会吗?半导体行业的一些有趣现象或许可以打开我们的思路。
英特尔一直在孜孜不倦的尝试突破摩尔定律的物理极限,经常会花费数倍于前一代产品的成本来推动CPU的更新与迭代,市场上经常会出现新一代CPU的价格是上一代产品的10倍,甚至百倍的情况。
追求性能的用户固然会追捧新一代CPU,可是在巨大的价差面前,仍然会有相当数量的用户选择使用上一代产品。
同样的道理,GPT-3和GPT-4在训练成本上有差距,同时随着大模型向前进化,训练成本的差距会更大,科技巨头探索在大模型的最前沿,在其身后会存在若干有代差、精度要求较低、“够用就行”的大模型,而这或许就是创业公司的机会,在成本、市场需求、技术进步的三者之间找到平衡,不断调整策略。
另外一个方面,深入行业的垂类大模型也值得一试,王小川表示,尽管垂类模型的通用性没法与OpenAI抗衡,但可以通过针对具体场景优化,在细分场景里达到与OpenAI相近的效果,从而积累用户、构建起生态,跑通小闭环。
关于大模型创业,360创始人周鸿祎就很乐观,“中国不会只有一个大语言模型,将来每个行业,企业甚至每个人都有自己定制的GPT大模型。”
结语
从长期来看,大模型是一场持久战,因而无论是现在入局,还是几个月或是几年后再入局,在本质上并没有什么区别,大模型竞争的核心不是抢速度,争第一,而是要沉下心来想清楚,在这场长跑中如何分配体力,如何获取资源,顺顺利利的跑到终点。
本文(含图片)为合作媒体授权创业邦转载,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







