8月30日,由创业邦主办的2023AIGC技术应用大会在深圳举行。本届大会以“元载万物·智启新界”为主题,旨在聚焦AIGC技术的创新应用,打造深入探索AIGC产业落地的交流平台。

会上,加拿大工程院外籍院士、HiDream.ai创始人兼CEO梅涛先生发表《AIGC 掀起未来创意无限可能》主题演讲,精彩观点如下:
1. 我们用AI辅助动漫生成,并非想取代电影工业,而是希望通过 AI 的手段激发创作者的潜力和想象力,提高生产力,进一步降低成本。
2. 预计在 2025 年到 2026 年之间, AI 辅助创作的图片和视频的数量将会超过人类自己创作出的数量,这也就意味着整个数字创意会被AIGC 所赋能。
3. 类似于自动驾驶,我们将AIGC的视觉创作能力可以分为5个档次,目前仍处于从 L2 迈进 L3 的关键阶段,未来还有很大发展空间。
4. 在AIGC涌现的时代,我们希望和有勇气的创业者一起,构建良好的生态,推动行业的发展。
以下为演讲/对话内容,由创业邦整理:
非常荣幸参加创业邦的活动,我今天将与大家探讨生成式人工智能在数字创意方面的可能性及技术发展趋势。
首先,我展示一部短片,这部短片是我们与北京电影学院的老师共同合作,其中所有的视频、画面、运镜都是由我们HiDream.ai 的创作工具Pixeling 生成的,没有用到任何第三方软件。
用人工智能生成一部影片,大概分为以下几步:脚本-分镜-关键帧-镜头生成-视频合成。相比于人工,借助AI工具制作影片的优势非常明显,一个人一到两个星期就可以完成;而若单纯依靠人工制作这样一部作品,从选角、场景到导演等环节,则至少需要一个月的时间。
AIGC重塑创意世界
我们用AI辅助动漫生成,并非想取代电影工业,而是希望可以提高效率、降低成本、提升创作体验。今天聚焦视觉AIGC话题,我首先和大家分享两个故事。
第一个故事是,一张AIGC生成的图片,曾在去年登上美国一家著名的时尚杂志封面。在这张照片中,“在浩瀚的宇宙中,一位女性宇航员在火星上,昂首阔步地走向一个广角镜头”所有关键词都被完美展现出来,而人类绘制一张这样的图,至少要花费一两个星期的时间。
另一个大家耳熟能详的故事是,一幅由人工智能工具生成的油画作品,获得了柯罗拉多州州立美术大奖,尽管引起了很多争议。

以上两个故事都在传递一个信号:AI 赋能艺术创作是大势所趋。下图所展示的数据也做出了预测↓
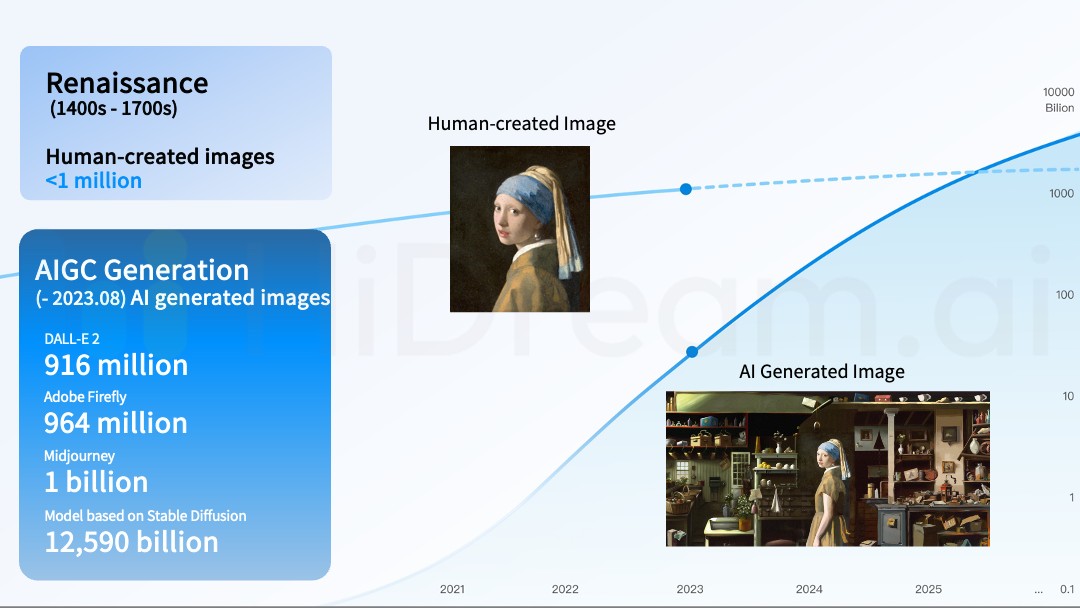
文艺复兴时期,人类创造了几十万幅绘画作品,但是留存下来的作品数量不到十万。现在,人类每天在社交平台上传的图片和视频的数量超过十亿。
在 2025 年到 2026 年之间, AI 辅助创作的图片和视频的数量将会超过人类自己创作出的数量,这也就意味整个数字创意会被AIGC 所赋能。
以世界名画《戴珍珠耳环的少女》为例,17 世纪荷兰画家约翰内斯·维米尔花了很长时间来创作这样一幅作品。但在今天,AI 可以将这位少女置身于厨房、咖啡店、沙滩等不同场景,大大丰富了原作之外的画面想象力。
生成式人工智能艺术创作的发展现状及未来
类似于自动驾驶,我们将AIGC视觉能力和创作能力分为5个档次:纯人工编辑→创意创作工具→部分生产力创作工具→完全生产力创作工具→设计大师。目前我们仍处于从 L2 迈进 L3 的关键阶段,未来还有很大发展空间。
事实上,从创意素材产生到进入整个工作流,还有很长的路要走。视觉生成领域要想创造出令人惊艳的作品,还面临很多挑战。
首先,在细节方面,我们经常会遇到“恐怖谷效应”,特别是手指,刚才在短片中,如果大家仔细观察,会发现手指控制其实并不理想。
第二个难题是,究竟应该用什么样的prompt 才能发挥大模型的威力。
第三个难题是可控性问题,包括IP可控、人物可控和SKU可控。此外,在视频制作中,还面临不同镜头之间的连续性问题等诸多挑战。
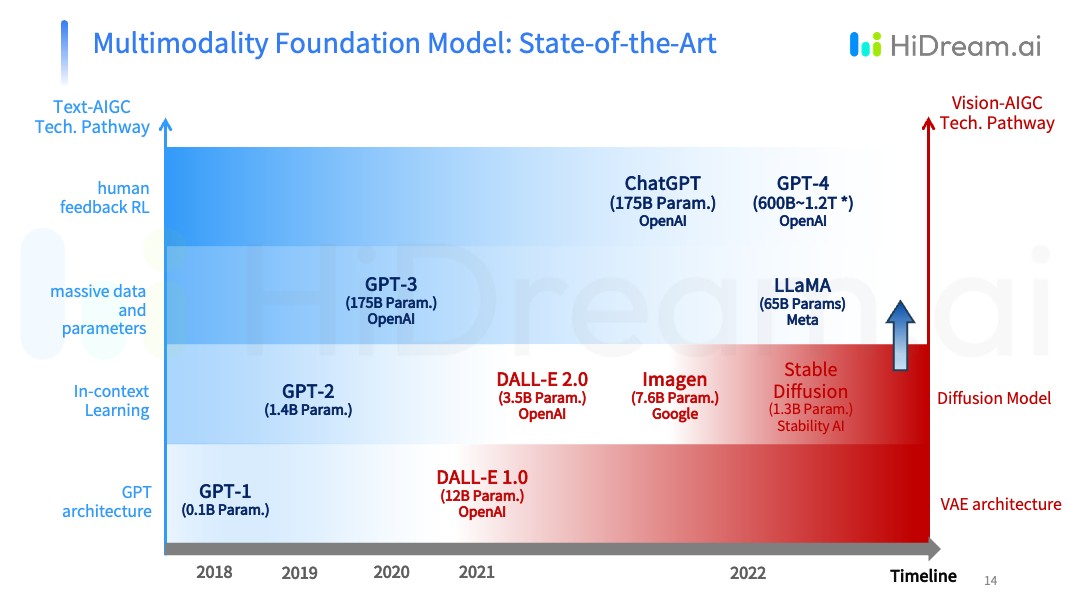
那么,视觉AIGC未来的想象空间到底有多大?有预测称,GPT-4可能已经达到了1.2万亿个参数,而GPT-5可能会更大。如果机器学习技术能够在未来几年,吸收和理解人类产生的高质量语言数据,这种增长可能会迎来一个新的天花板。
图片中红色部分是视觉AIGC能力表现,无论是Imagen还是Stable Diffusion,模型参数基本在几十亿,处于GPT-2的时代。我们想突破这个瓶颈,探索一个基于视觉的多模态底层大模型,能让视觉 AIGC从GPT-2时代进入到GPT-3时代。目前,我们自研的基础模型的数据量级已经达到60亿,我相信,很快也将达到百亿模型的目标。
Pixeling:掀起未来创意无限可能
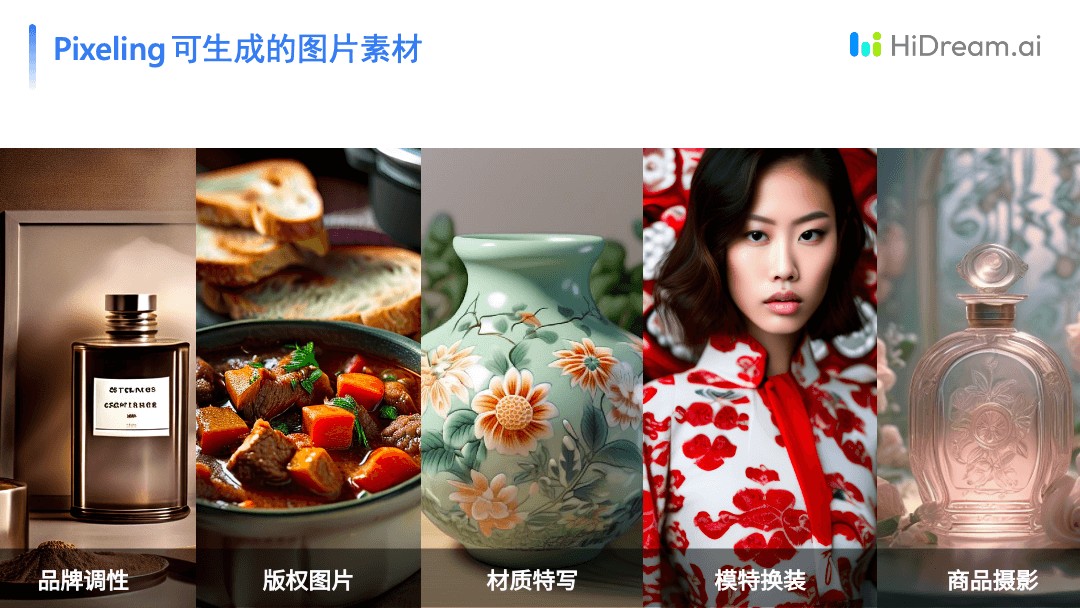
HiDream的产品Pixeling工具基于自研的生成式视觉多模态基础模型而打造,支持各种不同模态之间的转换,不仅支持文生图、文生视频、视频编辑,还将支持图片编辑、图生视频、图生 3D 等功能。以图片素材的生产的为例,涵盖品牌调性、版权图片、材质特写、模特换装、商品摄影等多种类型,目前有 16 种不同的图片风格可供选择。
Pixeling还支持文本生成视频以及图片生成视频,包括大家在影片中看到的最难场景是一个宇航员在月球上行走的全景画面,他还能够转一个弯,这其实是有难度的。除了背景运动外,我们还实现前景运动、人物运动和运镜。此外,我们的产品最近在学习镜头语言,包括镜头构图、运镜和剪辑等,希望为从业者提供一个更加节省时间,提升效率的创作工具。
在电商领域,Pixeling 能够根据用户提供的 SKU 图片,结合给定的 prompt 和背景图生成与背景无缝衔接的商品图片;如果用户没有给定背景图,我们也可以根据给定的 SKU 图片结合输入的多种 prompt 生成对应的商品图,几秒钟就可以完成。
产品问世不久,我们参加了香港中文大学发布的 HPS v2的文生图模型客观评测。该评测把包含绘画风格、概念艺术、动漫风格以及真实图片在内的 3200个prompt分别放在不同文生图模型里去验证。Pixeling1.0版本的模型上线和模型训练仅用了大约三个月时间,经过我们的测试,目前在该数据集的文生图模型中排名第二。
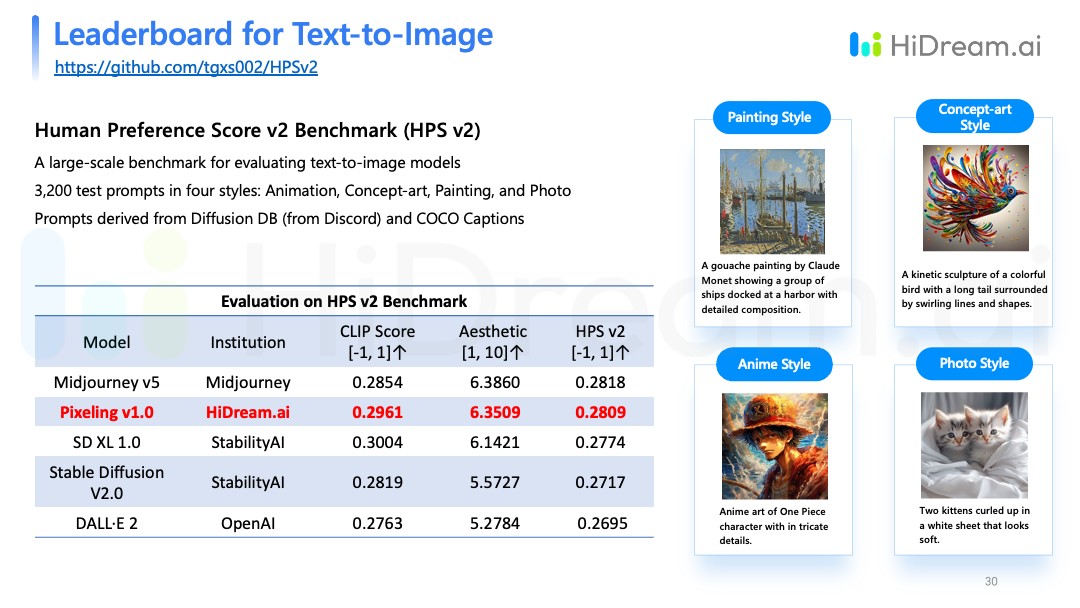 当然,Pixeling1.0版本现在的表现与最好的竞品还是稍逊一筹,但它终究是三个月的baby,我相信它未来一定会成长得更好。十分赞同其他嘉宾提到的AIGC“落地为王”观点,这也是我们今后努力的方向。
当然,Pixeling1.0版本现在的表现与最好的竞品还是稍逊一筹,但它终究是三个月的baby,我相信它未来一定会成长得更好。十分赞同其他嘉宾提到的AIGC“落地为王”观点,这也是我们今后努力的方向。
在AIGC涌现的时代,我们希望和有勇气的创业者一起,构建良好的生态,推动行业的发展。
再次感谢大家!







