编者按:本文来自微信公众号 硅星人Pro(ID:Si-Planet),作者 :油醋,创业邦经授权转载。
AI对人类世界的学习能力,到目前为止仍然停留在语言层面。
喂给大模型语料——最初是维基百科和Reddit,后来扩展到音频、视觉图像甚至雷达和热图像——后者广义上说是换了种表达方式的语言。也因此有生成式AI的创业者认为,一个极度聪明的大语言模型就是那个通往AGI最终答案,多模态的研究道路只是目前对前者的底气不足。
我们对未知生命族群的想象力以此为限(如果硅基生命也算的话)。当谈起外星生命,冲进脑子里的第一个想法是外星语言,《三体》里三体人的第一次亮相也是关于语言。这是人类文明的操作系统,推己及人,语言也会是其他文明的操作系统。《人类简史》的作者尤瓦尔·赫拉利在今年5月公开表达了他对生成式AI的担忧,掌握了人类语言的AI,已经有能力黑进人类的整个文明背后。
但AI对人类语言资源的占领,也是人类目前对AI威胁性的想象极限。换句话说,无法抽象成语言被表达和记录的东西,AI学不会。而世界处处是秀才遇到兵的故事,读万卷书不如行万里路,从周围环境中获取生活经验的本事,是人类面对AI的灵魂拷问时最后的自留地。
 图源:《三体》
图源:《三体》
直到DeepMind带着一篇新的论文出来,说这块最后的自留地咱说不定也守不住了。
DeepMind高级研究工程师,平时还顾着张罗一些非洲AI技术社群的Avishkar Bhoopchand,和在各种游戏公司做了5年然后去了DeepMind的Bethanie Brownfield领衔的一支18人研究团队,最近在《自然》杂志上发表了一篇新的研究成果。
简单来说,他们在一个3D模拟环境中,用神经网络结合强化学习训练出了一个智能体,这个智能体从未使用过任何预先收集的人类数据,但从零开始学习周遭的模拟环境,习得了人类行为。
在这场实验里,AI和“Culture(文化)”这个概念联系在一起,这好像是第一次。
广义上,谈及人类的“智力”,可以简单理解成有效获取新知识、技能和行为的能力。更实际点说,也就是如何在适当的情境中通过一系列行动以达成目标的能力。比如:
如何动用公式和辅助线解一道几何题。
如何把小红书上看到的一个菜谱变成晚饭餐桌上的一道菜。
如何开一家赚钱的公司。
都是智力的体现。
这篇论文里提到的例子更简单些——如何在一场游览活动中跟住导游,或者如何跟同事介绍一台打印机怎样用。
事实上,我们具备的很多技能都不是一板一眼学来的——比如如何教同事用一台打印机,反而人类的智力特别依赖于我们从其他人那里高效获取知识的能力。这种知识被统称为文化,而从一个个体传递知识到另一个个体的过程被称为文化传播(cultural transmission)。
文化传播是一种社会行为,它依赖整个群体实时以高保真度和高回忆率从彼此那里获取和使用信息,这最终导致了技能、工具和知识的积累和精炼,以及最终形成文明,在个体甚至代际间高度稳定发生的知识转移。而这整个过程并不是从一套经过设计的书籍或视频课开始的。
当AI研究者在担心喂给大模型的语料会在5年后枯竭,这首先建立在AI存在一个巨大的能力盲区的基础上,也就是直接从环境中将发散信息抽象化的能力。
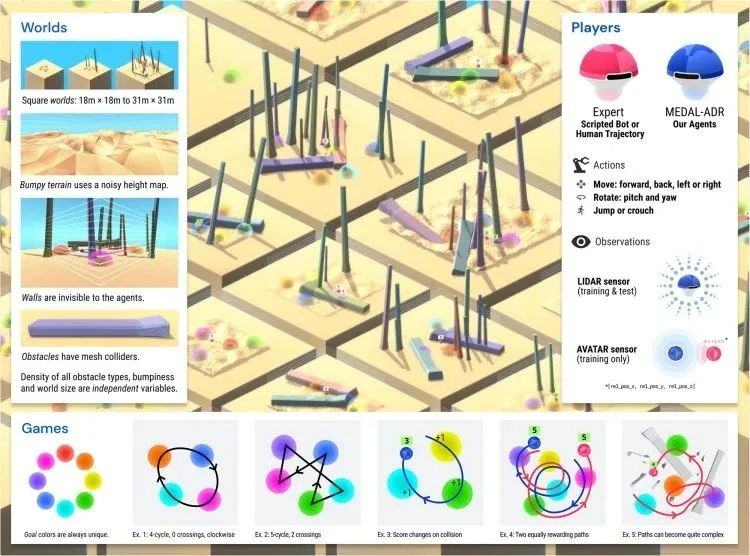
DeepMind在智能体的训练中引入了GoalCycle3D——一个在 Unity 中构建的3D物理模拟任务空间。看这张图片可以知道,这个空间存在崎岖的地形和各种障碍物,而在障碍物和复杂地形之间有着各种颜色的球形目标,按特定循环顺序经过目标球体会获得积极奖励。
 图源:Nature
图源:Nature
DeepMind在这个空间中设置了具有“上帝视角”,如何行动能够拿到奖励的红色方智能体,蓝色方智能体则是毫无游戏经验的“被训练方”。
拿到高分奖励即被视为一种“文化”。一个完全没有游戏背景的智能体所具有的文化传播(CT)值为0,一个完全依赖专家的智能体CT值设为0.75。一个在红色方在场时完美跟随,并在红色方离开后仍能继续获得高分的智能体的,CT值为1。
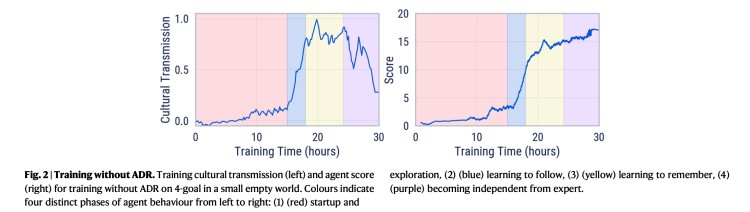
实验的结果是,在一个随机生成的虚构世界中,蓝色方智能体依靠强化学习完成对这种”得高分“文化的习得和超越,而这经历了4个不同的训练阶段。
第一阶段,蓝色方开始熟悉任务,学习表示、运动和探索,但在得分上没有太大改善。
第二阶段,蓝色方体有了足够的经验和失败尝试,学会了它的第一个技能:跟随红色方。它的CT值最终到达了0.75,表明了一种纯粹的跟随。
第三阶段,蓝色方记住了红色方在场时的有奖励循环,并在红色方不在场时能够继续解决任务。
最终的第四阶段,蓝色方能够独立于红色方智能体的引导,以自己的路线来取得更高分数。这表现在训练文化传播度量回落至0——也就是蓝色方不跟着红色方走了——但同时得分继续增加。更准确地说,蓝色方智能体在这个阶段显示出了一种“实验”行为,甚至开始使用假设检验来推断正确的循环,而不是参考机器人,也因此,蓝色方最终超越了红色方,更有效地得到了循环奖励。
这个以模仿学习开始,然后借助深度强化学习来继续进行自我优化甚至找到超越被模仿着的更优解的实验,表明AI智能体能够通过观察别的智能体的行为来学习并模仿这些行为。而这种从零样本开始,实时、高保真地获取和利用信息的能力,也非常接近人类跨代积累和精炼知识的方式。
这项研究被视为向人工通用智能(AGI)迈进的一大步,而如此重要的一步,DeepMind又是在一场游戏里完成的。
DeepMind曾经在另一种游戏中用零样本的方式完成过一次颠覆,只不过那次它颠覆的就是自己。而那个游戏——对,就是围棋。
2016年3月12日,李世石投子认负。这意味着人类在围棋这项人类自己创造的计算游戏中一败涂地,而甚至没有坐在对面的AlphaGO,在几个月的时间里完成了16万局棋谱的训练。
然后AlphaGO被击败了。
击败AlphaGO的是AlphaGO Zero——一个从没有看过任何棋谱,仅从围棋的基本规则开始一步步自学而成的AI棋手。那个纪念击败李世石的AlphaGO版本被称作AlphaGO Lee,AlphaGO Zero以100:0的战绩完全击败了AlphaGO Lee,而前者那时候仅仅训练了3天。
那时的AlphaGO Zero如同现在蓝色方智能体在GoalCycle3D里所呈现的一样,没有无监督学习,没有使用任何人类经验,最终跟上并且击败了自己的前辈。
在2016年以实习生身份进入DeepMind的Richard Everett,也是这篇论文的18人之一。玩电子游戏时人类玩家和看似智能的电脑控制玩家之间的互动让他着迷,也最终引导他进入了人工智能领域。这个关于“AI学习文化传播“的项目是他在DeepMind最喜欢的项目之一。
 图源:深度强化学习实验室
图源:深度强化学习实验室
“在世界上最大的糖果店里做个孩子”,Richard Everett这样描述他在DeepMind的工作感觉。而这篇论文的研究,要归功于来自艺术家、设计师、伦理学家、项目经理、QA测试人员以及科学家、软件工程师、研究工程师之间超过两年的密切合作。
AlphaGO Zero的成功让DeepMind在AGI研究中继续坚持着深度强化学习的技术路线,这才有了GoalCycle3D里所呈现的一切。现在这场通往AGI的大型游戏实验仍在继续。X平台上,Google DeepMind主页下最新鲜的一条推文是:
“欢迎Gemini。”
论文地址:
https://www.nature.com/articles/s41467-023-42875-2
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn







