
编者按:本文来自微信公众号机器之心(ID:almosthuman2014),创业邦经授权发布。
在计算机领域,提示词 (Prompt) 指的是算法输出之前的那段前置左向字符串。比如最早 MSDOS 下的 C:\>,Linux 下的~:,IPython 下面的 >>> 这些都算是提示词。在 2023 年,提示词已经成为和大规模语言模型 (LLMs) 互动最自然直观的方式。
如果将 ChatGPT 比喻成哈利波特小说中的绚丽魔法,那么提示词就像召唤魔法时的咒语。 能不能用好这个魔法,取决于你念咒语时是清晰明确,还是夹杂着 “口音”。 同样一个魔法,念咒的人不同,威力也不尽相同。所谓一千个读者就有一千个哈姆雷特,但一千个巫师的阿瓦达索命咒也不及伏地魔一个人念的有效(当然伏地魔念得再好也不如哈利念得有效)。
所以,能不能用好 ChatGPT 和大规模语言模型,很大程度上取决于你提示词的质量。事实上,不仅语言模型,包括几个月前很火的 DALL·E,Stable Diffusion 等 AI 文本到图片的生成模型,提示词对其生成艺术的风格和质量也有非常大的影响。

(同样是汉堡,同样是 Stable Diffusion 2.1 模型,左边汉堡中的提示词哪怕加了 "Trending on Artstation" 也令人没有胃口。那么问题来了,右边的提示词你能猜到是什么么?)
但说起提示词,难免让人爱恨交加。爱的人把它视为技术与艺术的融合,恨的人把它看做阻碍机器学习和 AI 前进的绊脚石。
ChatGPT 创始人 Sam Altman 认为提示词工程(Prompt Engineering)是用自然语言编程的黑科技,绝对是一个高回报的技能。 网络和论坛上搜集、整理甚至高价出售、悬赏提示词的比比皆是。很多人把提示词看做 AIGC 这个时代的源代码,对应的网课已经开始涌现。
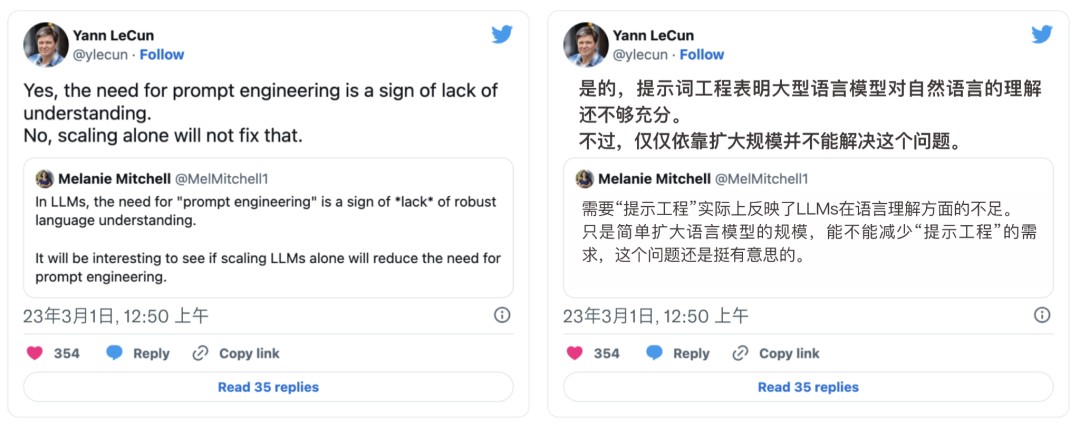
与之相对应的, 人尽所知的深度学习巨头 Yann LeCun 却认为,提示词工程的存在是因为 LLMs 对真实世界理解的不足 。他觉得 LLMs 需要提示词只是一个临时态,这恰恰说明了当前 LLMs 还有很大的改进空间。随着 LLMs 技术的不断革新,LLMs 很快会具备理解真实世界的能力,到那时提示词工程就失去了存在的价值。
未来太远,但就目前 LLM 的发展来客观讲,提示词的存在是有一定意义的。正如在现实世界中人与人的互动需要一定的沟通技巧一样, 你也可以把提示词看做人与机器互动时的沟通技巧 。好的提示词可以帮助你在使用 LLMs 时取得更好的结果,这就像在现实世界中,口才出众、能说会道的人往往可以更快速地协调完成工作。
尽管在 2023 年,自然语言已经鱼跃成为了人和人、人和机器之间沟通的统一方式,然而与 LLM 机器 进行沟通还是比与人交谈更具挑战性。首先,LLM 无法像人类一样理解细微差别、语气或上下文,这意味着需要仔细设计提示词,使其明确且易于被模型理解。你可以想象你叽里咕噜对 LLM 说了一大堆,然后 LLM 冷淡地回复了一句 “说人话”。
其次,由于训练语料的限制,LLMs 在语言理解方面可能存在一定的局限性,一些现实世界中的长逻辑表达,铺陈、反转、甚至是简单推理归纳在 LLMs 中不能被完美的理解和执行。
而 LLMs 中因为训练语料中而产生的一些暗语(比如 GPT 中最著名的 "Let's think step by step / 让我们一步一步思考" , "Below is my best shot / 下面是我最好的一次预测")在人与人的日常沟通间反而不常见。这些都使得提示词工程进一步复杂化,晋升为所谓的 “玄学”。
对于母语非英语的中国用户来说,提示词也是阻碍大家对 LLMs 尝鲜的最大痛点。 回想 2022 年暑期 Midjourney、Stable Diffusion 在英语市场如日中天时,国内的社区反应并不热烈。究其原因,还是因为 Midjourney、Stable Diffusion 的提示词以英文为主,在构建时需要大量的词汇和流行文化储备。这对于想尝鲜的中文用户都极其不友好。
ChatGPT 之所以能够在中文社区火爆,一部分原因也得力于其在中文上的良好支持,这极大地降低了中文用户的门槛。汉语作为世界上使用量数一数二的语言,仍然被提示词绊了一个小跟头;自郐而下,小语种究竟有多难可想而知。
总而言之,提示词工程的存在具有它的合理性。一个好的提示词也确实能带来事半功倍的意义。好的提示词能够帮助我们了解大语言模型的能力和边界,深入挖掘它的潜力,从而在生产实践中更好地发挥其作用。
这其中最著名的例子就是 上下文学习 (In-context learning)。

用魔法打败魔法
图源@Jina AI
在现实中,提示词的优化过程需要反复试错迭代,极其繁琐;并且还需要一定的知识储备。这就不禁让人发问,在 AI 当道的今天,提示词能不能也自动生成?
在 Yann LeCun 抨击提示词的推文回复里,我们注意到了这条回复:“提示词工程就如同对科学中对待一个问题的描述和定义;同一个问题,在不同人的描述下,或优或劣、或易或难、或可解或不可解。所以,提示词工程的存在并没有错,而且提示词工程本身也可以被自动化。”
这位网友同时还给出了一个产品: 「最美提示词」(PromptPerfect.jina.ai)。 也就是说,这种 用算法来优化提示词 的新范式已经被成功实现了!
这条回复中提到的 promptperfect.jina.ai 用魔法驯化魔法,让 AI 指导 AI,当你输入提示词后,它就会输出优化后的「最美提示词」,并让你预览优化前后的模型输出。这样就实现了从 “garbage-(prompt)-in-garbage-(content)-out” 到 “好输入 - 好输出” 的良性循环。根据产品的官方文档介绍,其不仅支持当下最火的 ChatGPT 提示词优化,还支持 GPT 3、Stable Diffusion、Dall-E。接下来就让我们来测评一下这位 “AI 提示词工程师” — 最美提示词(PromptPerfect)究竟有哪些科技与狠活。
如何 10 秒钟内轻松优化提示词?
1、将口语需求变成条理清晰的提示词
优化提示词需要理解语言的构造,知道哪些句子哪些词能够 “启动” LLMs 的智能。如果没有这些储备,提示词含糊不清,如口语一团乱麻,那么就容易被 LLM 带沟里。“最美提示词” 可以从海量数据中学习并深入理解更深刻的语言知识,以产生更加准确、清晰、有效的提示词,不管想要什么样的需求和任务,都能 直接量身定制,提供最精准的表述。

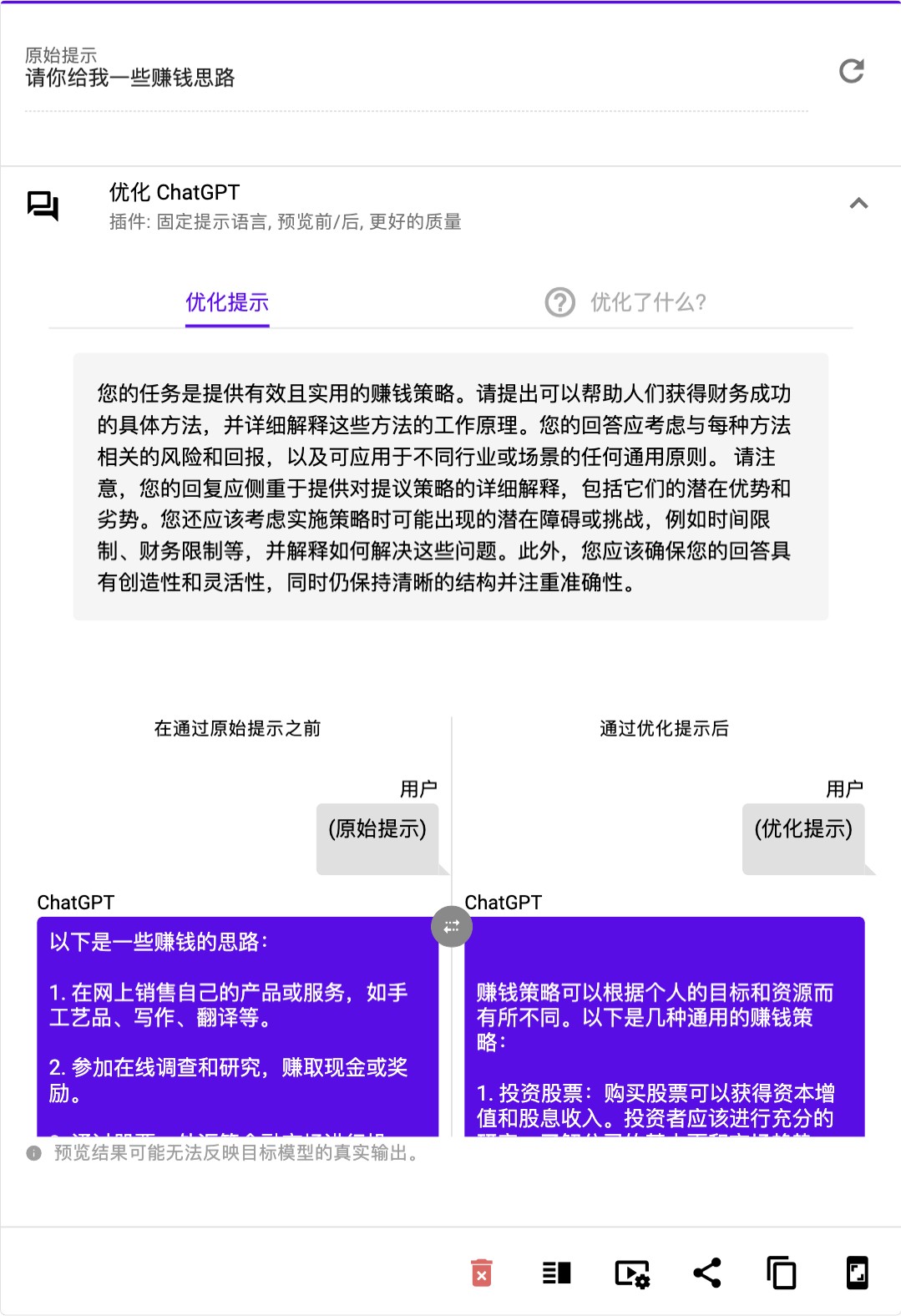
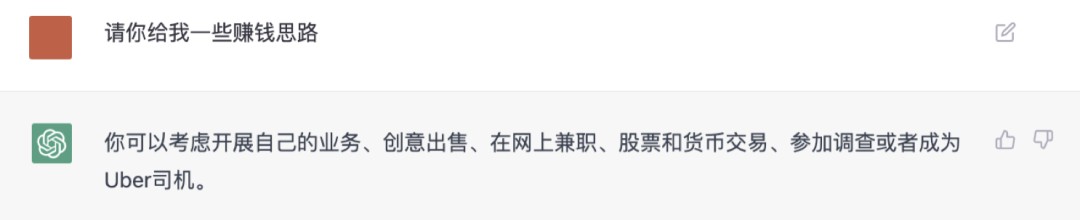
面对 GPT3 或 ChatGPT 时,提示词卡壳可能是因为沟通能力有限,难以表述清晰的问题或指令,严重影响到模型的回答质量。我们尝试用「最美提示词」优化一些常见指令,如下图,「最美提示词」 把原本简略粗糙的提示词 “请给我发一些赚钱思路” 进行了上下文的扩展,输出了一条堪称完美的提示词:
手动输入靠运气

使用「最美提示词」靠科技
相比原始提示词,「最美提示词」 定义了明确的目标、清晰的产出,还给 ChatGPT 补充了情景式铺垫的逻辑 ,使得 ChatGPT 生成的措施更具实操性,效果的确肉眼可见地得到了大幅改善。
2、轻松拿捏不同的 LLMs/LMs 的 “话术”
不同的 LLMs 有不同的脾气和习惯,想要与他们进行有效沟通,就需要学会当地的话术。否则就很容易形成鸡同鸭讲。就好比当你好不容易掌握了 Stable Diffusion 咒语,结果发现 ChatGPT 的对话方式就完全不同,一切积累从头再来。“最美提示词” 帮用户就免去了对不同模型的学习成本,不论是 ChatGPT、GPT 3、Stable Diffusion 还是 Dall·E 等, 只要选择模型,就可以一键就能优化最合适的提示词。
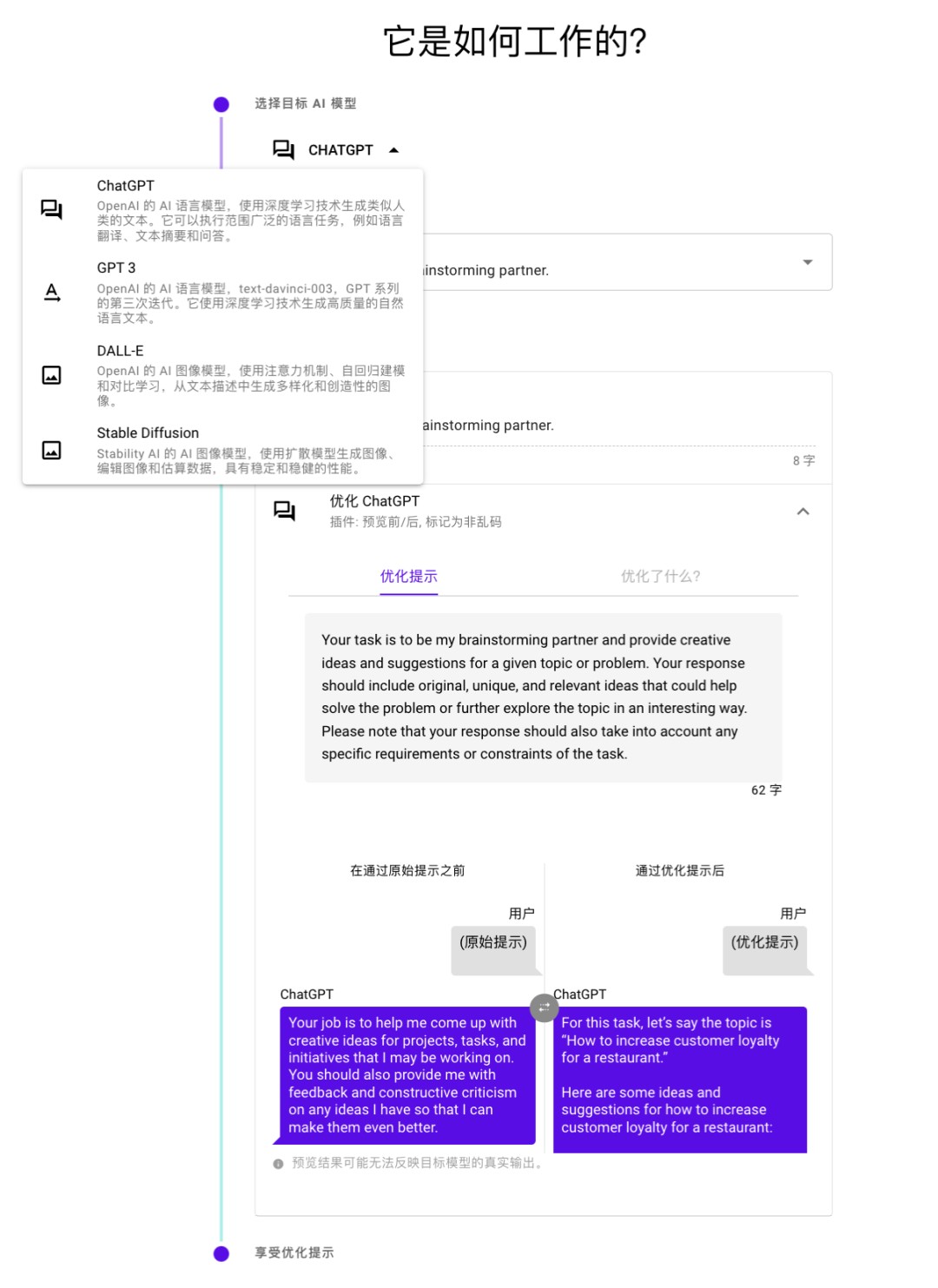
3、中文提示词一键优化生成完美英文提示词
跟单模态的 ChatGPT 比起来,在 AI 绘画领域,英文说不好就是难下笔。就算囤了一堆提示词,也可能因为词汇量不够,不知道怎么描述,找不到合适的提示词而郁闷。「最美提示词」 可以把你用中文想的提示词直接变成英文的提示词 ,让你用起来更顺手,效果也更棒,不用再费劲去学习各种英文形容词,中文用户也能轻松上手。
有时候我们用 DALL・E 或 Stable Diffusion 生成图片时,会觉得很难出效果。这可能是因为我们英文不够好,也可能想象力不够丰富,没法想出具体的图像或场景。所以出来的图片就很模糊或者很奇怪。
我们尝试用「最美提示词」优化一些常见指令,比如说,下图,「最美提示词」把原来简单粗糙,略显无聊的 “印象派的北京街景” 改成了一句带有丰富描述,超级赞的英文!
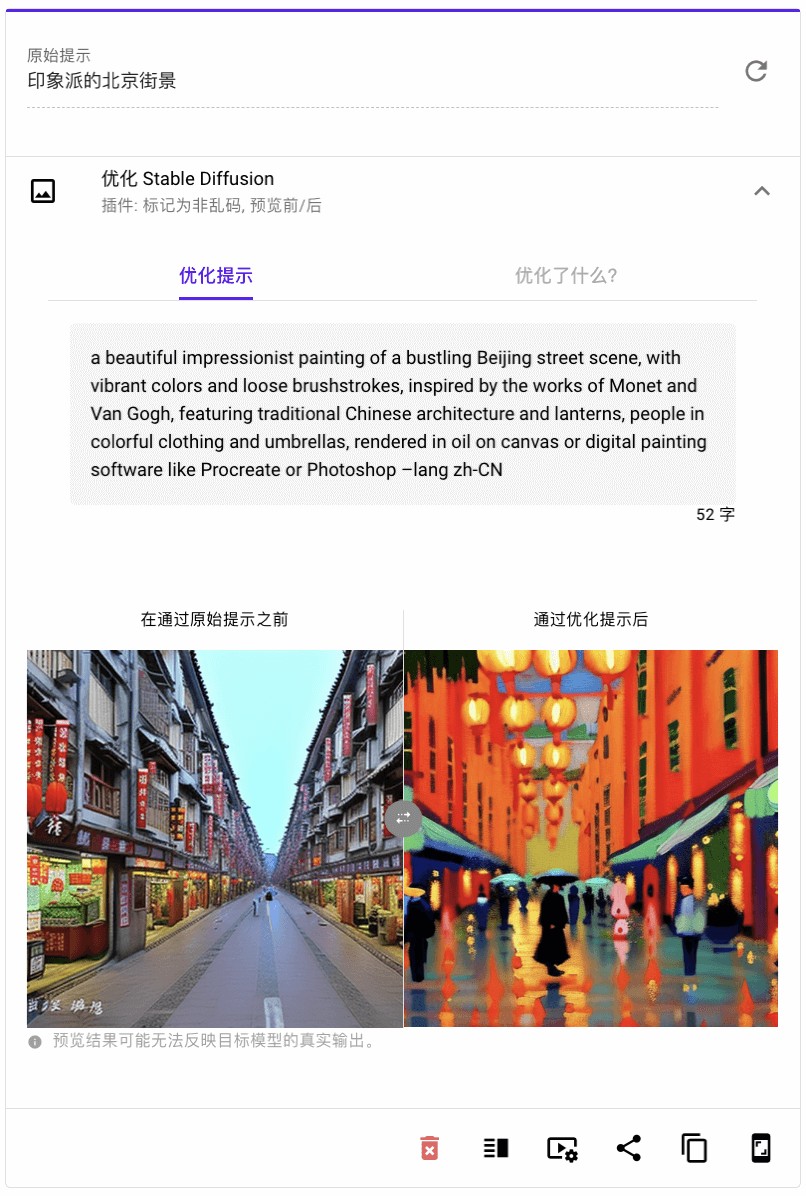

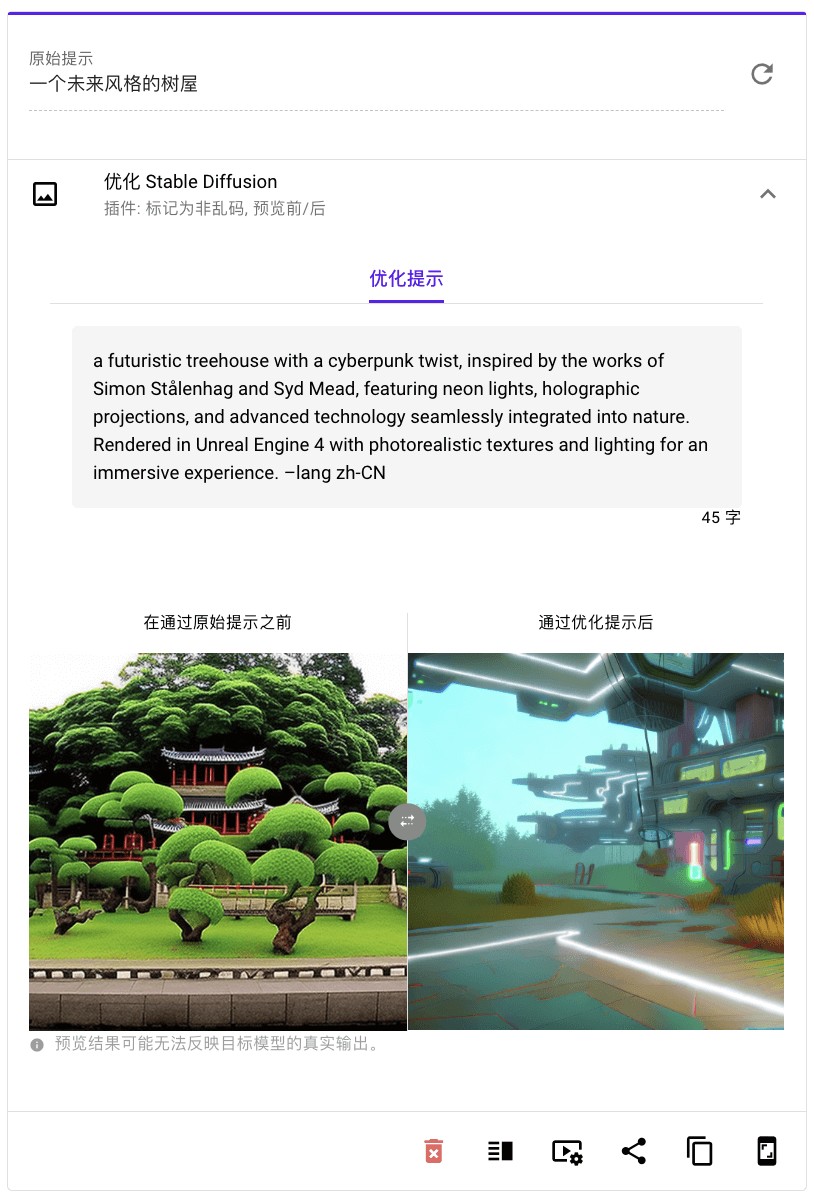
优化前的提示词完全显示不出来印象派、耳机、未来风格
AI 绘画的提示词测试起来更加一目了然,「最美提示词」生成了冗长但无比精准的 “咒语”,直接提升了原始提示词的审美、想象和阅历,使得画面更生动,更准确地表达了我们原本的期望。
4、开发者可直接调用的 API
想要大批量优化提示词,或是直接在现有系统中集成,那么 可以直接调用「最美提示词」的 API ,这样可以更快地生成批量的优质提示词 ,不管你需要多少个提示词,「最美提示词」都能为你快速完成,提供最优质的服务。

背后的技术与团队
我们注意到「最美提示词」自 2 月 28 日一经推出以来,就引发了大量关注,大家都想要用它来优化各种场景的提示词。短短 几天之内 就吸引了 数千用户 优化了近万提示词,在各类平台狂揽好评。毕竟只要用了它生成的提示词,就能让大模型出来的东西既有创意又有美感。
「最美提示词」要给各种语言模型找到最好的提示词,它用了两招高级的机器学习技术: 强化学习和上下文学习 。强化学习就是它的教练,一直在给它灌输知识和经验,让它变得越来越厉害。
它先用一些人工筛选的提示词给一个预训练模型打好基础,再根据用户输入和模型输出来调整提示词网络策略。比如说,当我们要优化 DALL・E 和 Stable Diffusion 的提示词时,我们要让生成的内容既有关联又有美感,就像教练要求运动员在各方面都表现得非常优秀。
上下文学习就是它的老师,通过多个例子来教它怎么学。但是它不是把所有的例子都堆在一起,而是把很多的例子分成几组,然后让语言模型自己去编码。这样「最美提示词」就可以用更多的例子来教模型,从而生成更准确、更有效的提示词。通过用这两招,「最美提示词」就可以为各种语言模型优化提示词,显著提升效率和准确度,就像一个由教练和老师一起培养出来的知名运动员。
这种大规模的生成式模型,无论是语言生成模型还是多模态的生成式模型,在目前是以语言为主。 然而,在未来,我们肯定会看到更多多模态的生成式模型的出现。
我们发现「最美提示词」的研发团队其实正是专注于多模态 AI 的新兴技术公司 Jina AI ,成立于 2020 年,总部位于德国柏林,在北京深圳均设有研发。Jina AI 专注于多模态 AI 技术研发,在搜索和生成领域都有广泛的应用,此前 Jina AI 已经发布了一系列如下的开源的项目,在 GitHub 累计收到来自全球开发者将近四万星星的关注,为开发者快速实现多模态 AI 应用提供了方便:
多模态 MLOps 框架 Jina:
https://github.com/jina-ai/jina
专为多模态数据而生的数据结构
DocArray:
github.com/docarray/docarray
CLIP-as-service:
github.com/jina-ai/clip-as-service
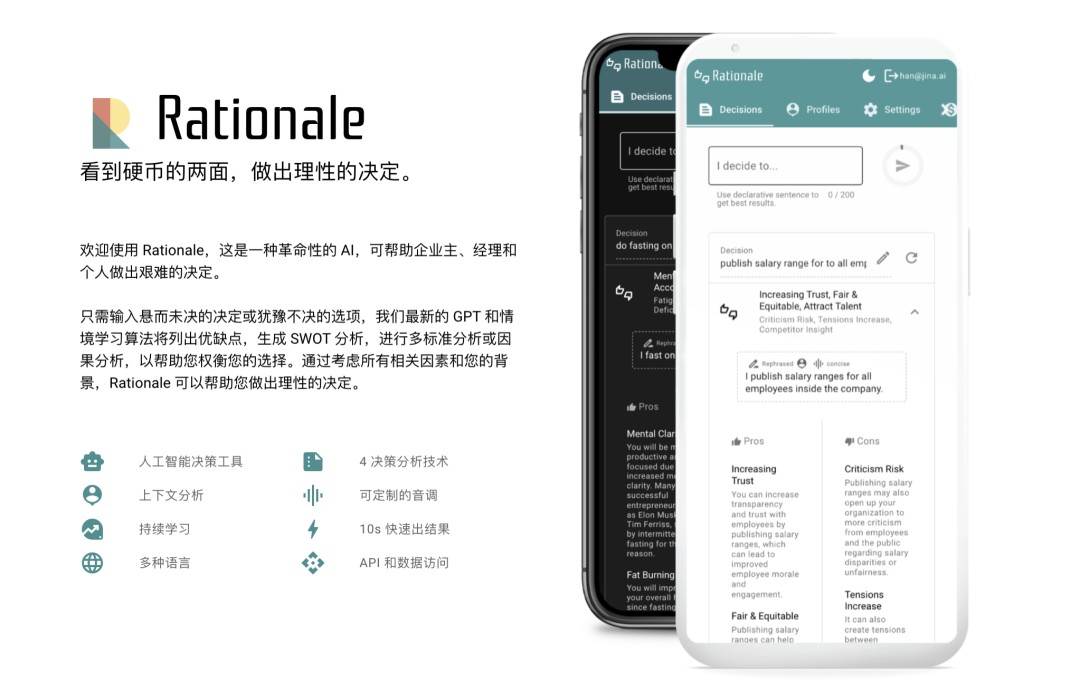
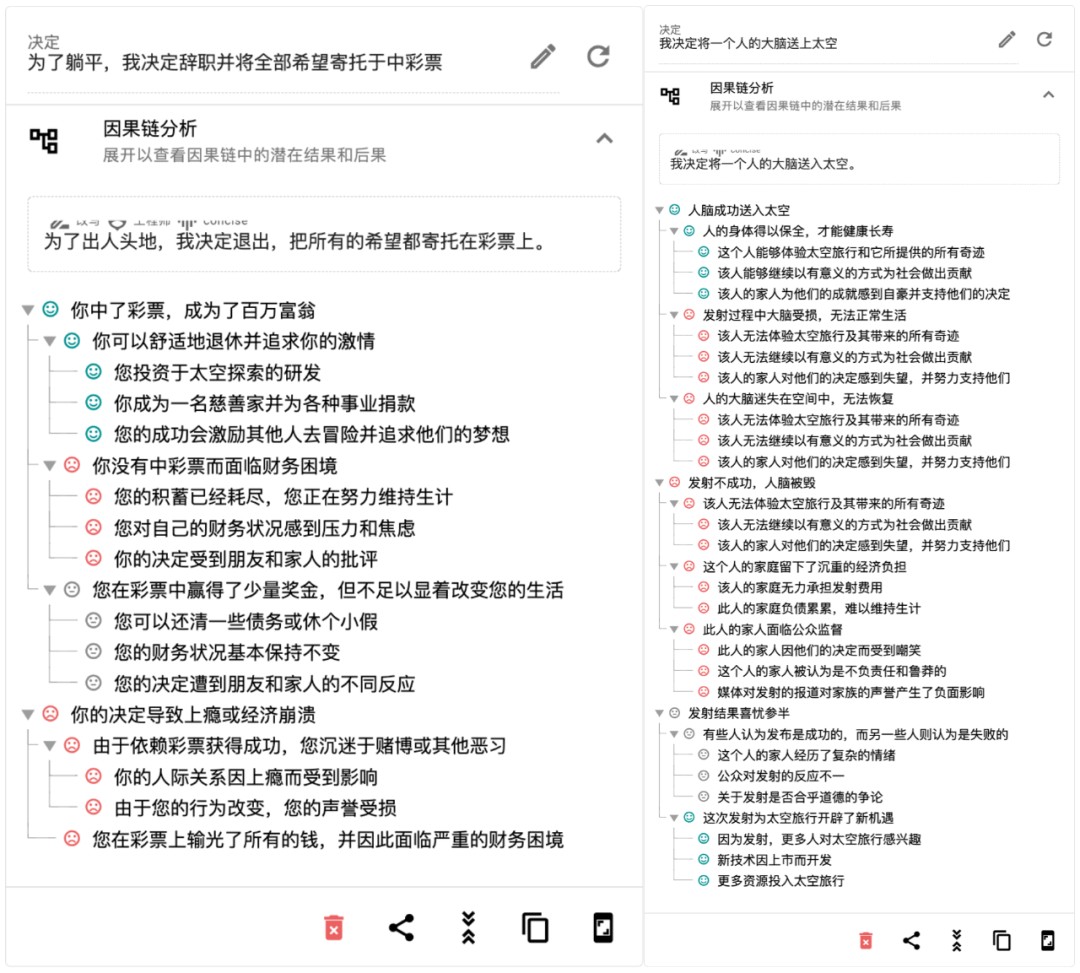
在这个生成式 AI 海啸般地突破了多种模态壁垒的时代,「最美提示词」可直接提高大模型生产力,带来效率上地显著提升,我们同样注意到 Jina AI 还研发了 Rationale(rationale.jina.ai),基于 ChatGPT 的 AI 决策工具,只需输入心中所想的一个或几个决策,Rationale 10 秒内就能为你生成一份专属的决策评估报告。它可以用于咨询、评测、调研、策划、汇报等场景,提高决策效率。
作为一款具有 “批判性思维” 的人工智能决策工具,Rationale 能通过帮助大家列出不同决策的优缺点、生成 SWOT 报告、进行多标准分析或因果分析等拓宽思路、提炼观点,做出理性的决策。2023 年或将成为初创企业改变游戏规则的一年。
随着 ChatGPT API 的开放,2023 年面向 C 端的 AI 应用就像 2000 年互联网时代一样,形成井喷式大爆发:每天都有数以百计的 ChatGPT API 的应用面世,它们遍布各个领域,打破了现有的规则,并颠覆了多个领域的生态。一些传统巨头面临挑战,一些传统的壁垒面临打破,一些传统行业面临革新。而对于我们来说,想要在 AI 新时代站稳脚跟,就得站在巨人的肩膀上,吟诵出完美的咒语,用魔法来解决各类生成任务,毕竟完美的提示词就是一个 ChatGPT 应用的灵魂所在。
本文(含图片)为合作媒体授权创业邦转载,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







