
编者按:本文来自微信公众号 星船知造(ID:xingchuanzhizao),作者:唐晓园、钱伽诺,创业邦经授权转载,头图来源摄图网
一则来自美国的消息暂时打破了此岸AI大模型创业者和资本们时而亢奋时而抑郁、时而趋之若鹜时而谨慎保守的叙事节奏。
美国《华尔街日报》27日援引知情人士消息称,美国商务部可能最快在下月初采取行动,禁止英伟达等芯片制造商在事先未获得许可证的情况下,向中国和其他相关国家的客户出口芯片。
英伟达今年年初刚对公司旗舰芯片进行了调整,以符合向中国出口的法规。
据路透社29日消息称,英伟达首席财务官科莱特•克雷斯表示:
“从长远来看,如果实施禁止向中国出售我们的数据中心图形处理单元(GPU)的限制措施,将导致美国产业永久丧失在全球最大市场之一竞争和突出的机会,并对我们未来的业务和财务业绩产生影响。”
01 无尽前沿的回响
1945年,美国二战时期工程师范内瓦·布什,如同穿越者一般向白宫递交了一份报告。70多年来,这份报告对美国科研决策和发展的影响绵延至今。
《21年美国创新与竞争法案》被认为是对《科学:无尽的前沿》中主要观点的延申和致敬。
报告核心观点:一是从战略上明确科技立国。明确美国要在“医学和基础科学研究”、“涉及国家安全的研究”等方面重点投入科研。
二是为了达到这个目标,政府该扮演怎样的角色。首先政府应坚定投入公共资金支持基础研究。其次是注重长期回报,在不计成本培养科学人才的同时,鼓励企业加大科研投入等。
今天的环境与冷战时期和热战时期又截然不同。随着以ChatGPT为代表的生成类AI大模型的横空出世,“国产大模型是否存在自主可控”的问题在中美人工智能领域存在差距的现实背景下被频频提及。
作为一种生成逻辑,与其说大模型的自主可控,不如说“算力平台的自主可控”和“确保国家数据主权”。
星船知造文章《算力时代下的中国云:读懂中国式现代化必要的数字底层》中写过:数据是数字经济时代重要生产要素。《中华人民共和国数据安全法》中明确指出,数据是国家基础性战略资源,没有数据安全就没有国家安全。
中国目前正通过建设自主可控的数字基础设施,来保障国家数据安全。确保核心数据始终掌握在自己手中。
中美在人工智能领域的一些差距是显而易见的。
主要体现在以下几个方面 (更多可点击《星船知造ChatGPT技术架构及中国人工智能未来发展趋势报告》或后台回复关键词“白皮书”,下载高清完整版报告)
首先是中国在AI芯片上的落后。
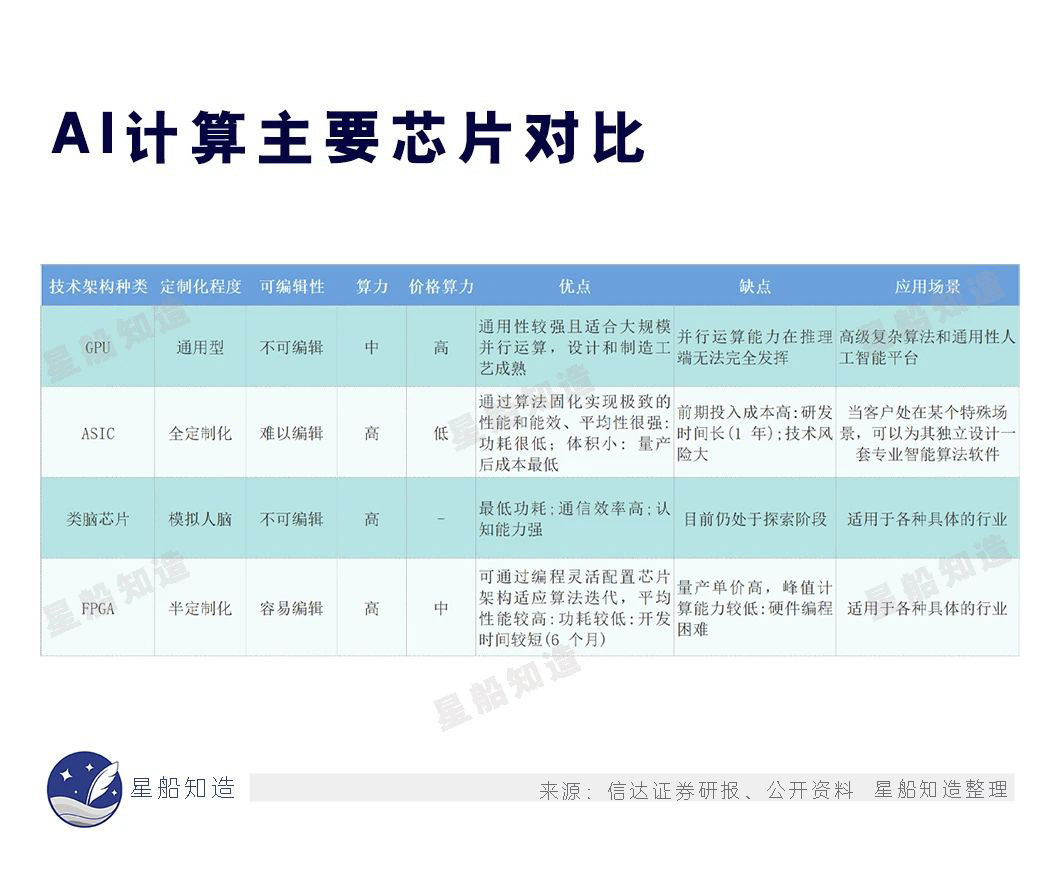
AI芯片引进方面:美国此前将特定高性能芯片、高性能计算芯片加入了商业管制清单。其中就包括AI最主要的英伟达A100和H100系列以及AMD的MR1250等高性能人工智能芯片。
6月28日,据《华尔街日报》周二援引知情人士的话称,美国正在考虑对向中国出口人工智能芯片实施新的限制。
在以ChatGPT为代表的生成类AI大模型中,对于AI芯片的要求更高,包括要求更高速的内存带宽、更大的内存容量以及更加高效的数据通信带宽。
集成电路芯片加工领域:台积电已经可以生产3纳米的芯片,目前中国芯片制造排名第一的中芯国际,生产14纳米的芯片,差距十分明显。
其次是美国对华出口AI芯片速率方面的限制。
OpenAI不仅使用本公司的物理服务器和数据中心,同时也会使用微软位于华盛顿凤凰城,德州圣安东尼等多个异地的超算中心。然后将结果同步到自己的计算机上,以达到加速训练和提高模型性能。AI芯片的高速互联的性能指标,对于人工智能大模型的训练将会起到至关重要的作用。
美国政府对华出口的英伟达公司AI芯片输出速率加以了严格限制,明确提到了要限制600GP/秒互联宽带以上的AI芯片的出口。
英伟达公司因此为了继续能向中国出口AI芯片,赚取利润同时又不违反美国政府的管制要求,向中国提供特供版的A800芯片,用于替代A100芯片。A800的高速互联通信速率降为了400GB/秒,而美国本土使用的A100产品的高速互联通信速率为600GB/秒,这种降级指标会对AI系统的性能造成很大的影响。
再者是芯片加工是阻碍我国大模型进展的一环。
目前英伟达A100芯片是采用台积电7纳米工艺制作完成,而M1250采用的是台积电6纳米工艺,英伟达H100采用的则是台积电的4纳米工艺,第四代的NVlink GPU之间的传输速率达到了900GB每秒。美国政府限制对华出口AI芯片,就是利用技术手段有针对性遏制我国人工智能和大模型训练模型的步伐,保证美国始终处于人工智能发展的制高点。
NVIDIA 护城河是从应用、软件、到硬件的一整个生态系统。
除开硬件对中国算力的部分掣肘,发展人工智能三大要素:数据、算法、算力中的另两样——
数据层面,到2022年底,中国网民接近11亿。每次对互联网的触摸,都是对某类青涩数据的填补。作为拥有全球最大规模网民群体的国家,我们在数据和应用场景上保有优势。(更多可点击《全国人民用20年为中国互联网找到解题新思路》)。
算法层面,国内科研机构和企业大炼千亿级大模型,底层算法中国并不落后。
另一个问题就是,任何攻坚都要花大钱。
据OpenAI 测算,训练一次ChatGPT模型的算力成本在450万美元左右,还只是计算硬件投入的成本,不包括人工成本、网络宽带成本、数据储存、固定资产折旧等的综合成本。比如OpenAI训练GPT3的费用可高达1200万美元,训练GPT-4成本可高达1亿美元。
人力成本和运维成本支出也占据总成本很大一部分,OpenAI就雇佣了大量第三世界国家的外包员工来完成指定的优化任务降低人工成本。
对于创业公司来说,融个几亿都不够烧的。
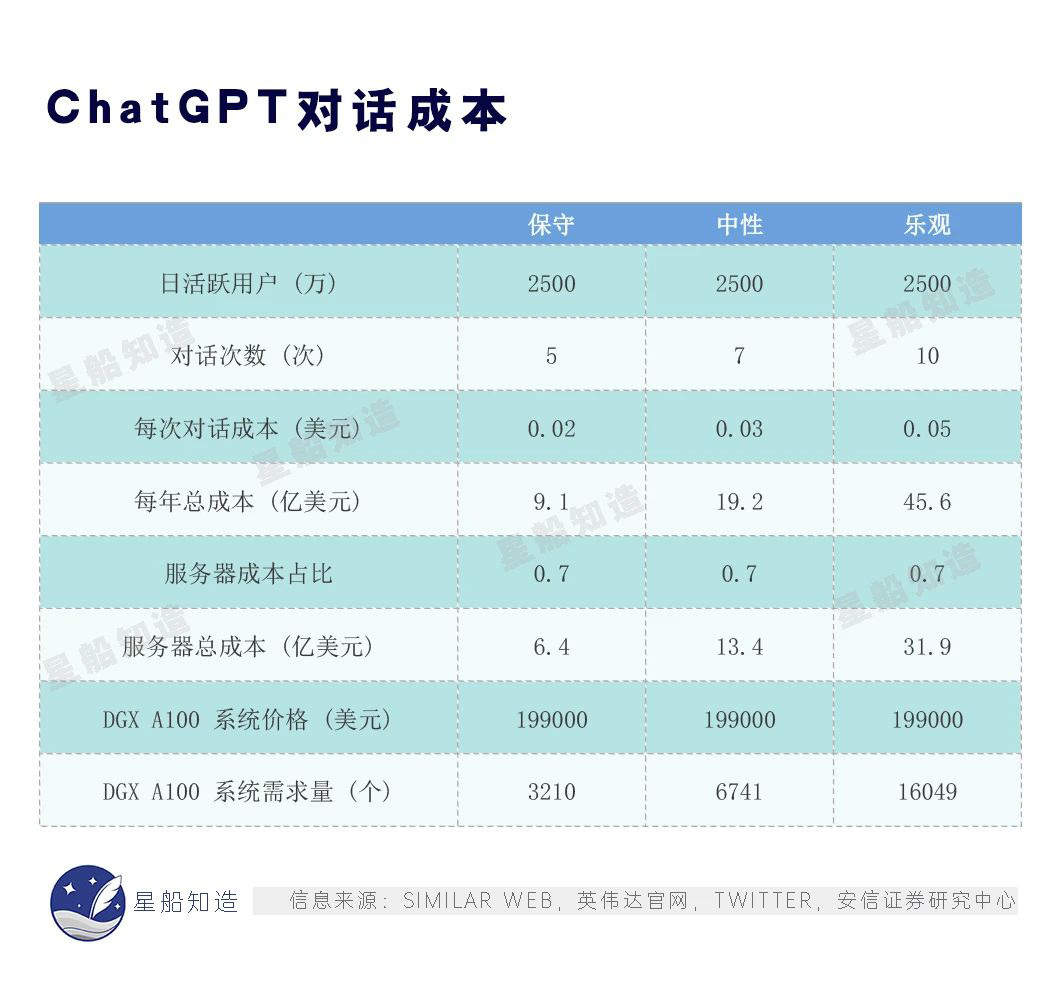
初创后很长一段时间里,OpenAI都是一家非营利组织。之后的横空出世,一靠微软输入巨资,二靠背靠巨头带来的业务加持。
今年春节前后,被大模型出圈首先刺激到的,是创业者和投资人。
02 浪潮之下,泡沫和厮杀的加速器
抑郁和焦虑如同一对双生子。最开始的症状则表现为亢奋。
GPT从3.5到4.0仅历时105天。但仍比不上中国创业者的速度。《中国人工智能大模型地图研究报告》显示,截至今年5月,中国已发布了79个人工智能大模型。王小川4月宣布创业,6月产品就出来了。光年之外更是在几个月的时间内完成了从成立、融资、创始人抑郁、被收购的一整个过程。
大模型的亢奋还在。但回头看看元宇宙……某地刚争到“元宇宙第一城”的名号,元宇宙就在大模型的映衬下看起来像凉了。
去年此时PPT上的元宇宙造车还没搞明白,今天已经铺天盖地自动驾驶大模型了。
某位不愿透露姓名的投资人在参加完一场以大模型和人工智能相关项目为主的路演后对我们表示,大部分项目提到的“大模型”定义都相当含糊,听上去换个别的词也OK,比如大数据、虚拟人。
曾借元宇宙概念炒作的事物将在大模型时代加速凉透。但元宇宙本身具备杀手级应用一切特征的本质不会改变。从包含的技术、已有的政策扶持、可能的产业落地回看,元宇宙都没有理由被大模型挤得彻底褪去热度。
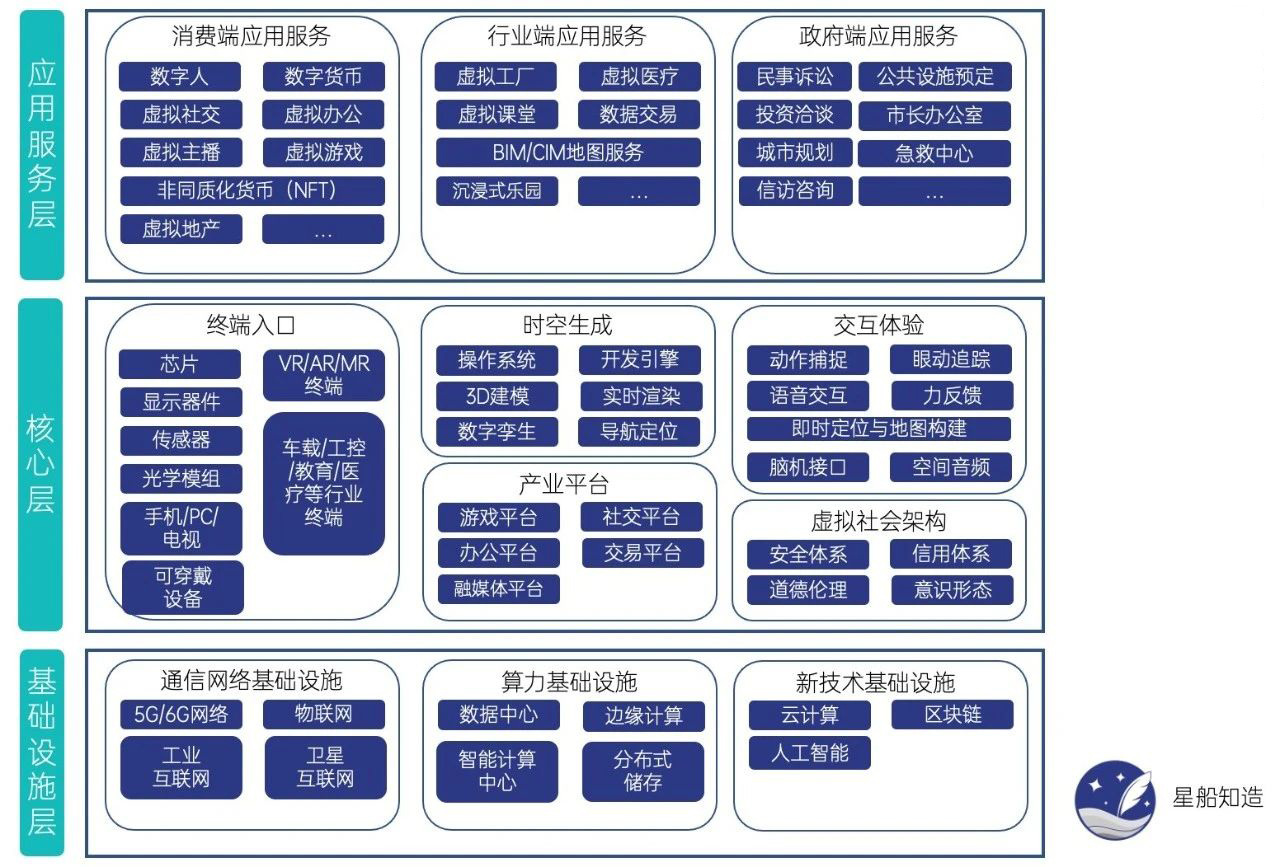
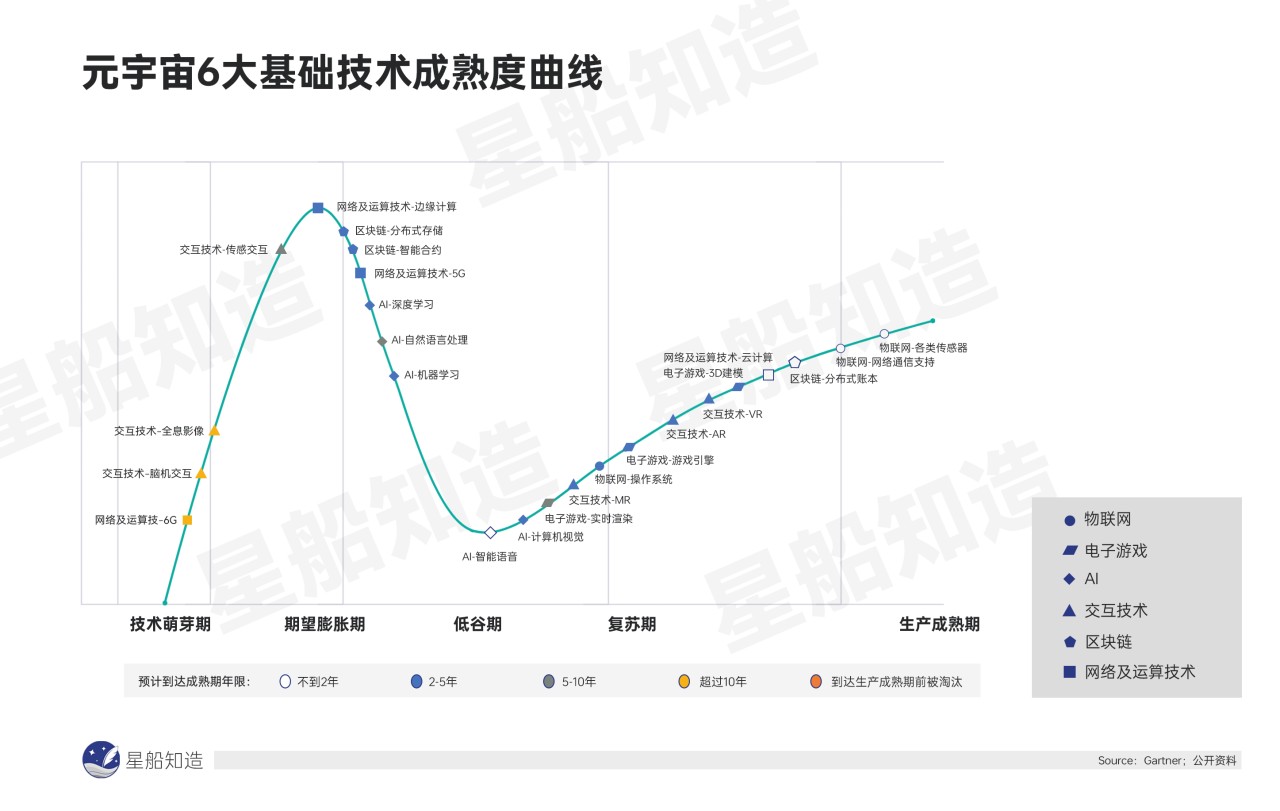 包括上海在内,目前全国各地仍在出台政策扶持当地的元宇宙产业。今年6月《上海市“元宇宙”关键技术攻关行动方案(2023—2025年)》印发,明确提出以沉浸式技术与Web3技术为两大主攻方向。
包括上海在内,目前全国各地仍在出台政策扶持当地的元宇宙产业。今年6月《上海市“元宇宙”关键技术攻关行动方案(2023—2025年)》印发,明确提出以沉浸式技术与Web3技术为两大主攻方向。
目前大模型能带来的商业回报谁也不敢保证,但极度烧钱是确定的——资本因此呈现出狂热和谨慎的两面性。
ChatGPT1早在五年前就已发布。同时AIGC(AI-Generated Content 人工智能生成内容)也早在ChatGPT3.5爆火的22年底之前,就已凭借去年的“AI绘画”获得一定关注。借助AIGC技术,可进行文章、视频创作、音频剪辑、游戏开发等工作。只是其热度始终没有真正破圈。
无视AIGC的投资人同样在去年年底无视了ChatGPT。直到今年春节后,再聊不上几句GPT就会彻底暴露自己在新一轮科技周期中的无知——一场围绕新周期的狂热才就此展开。
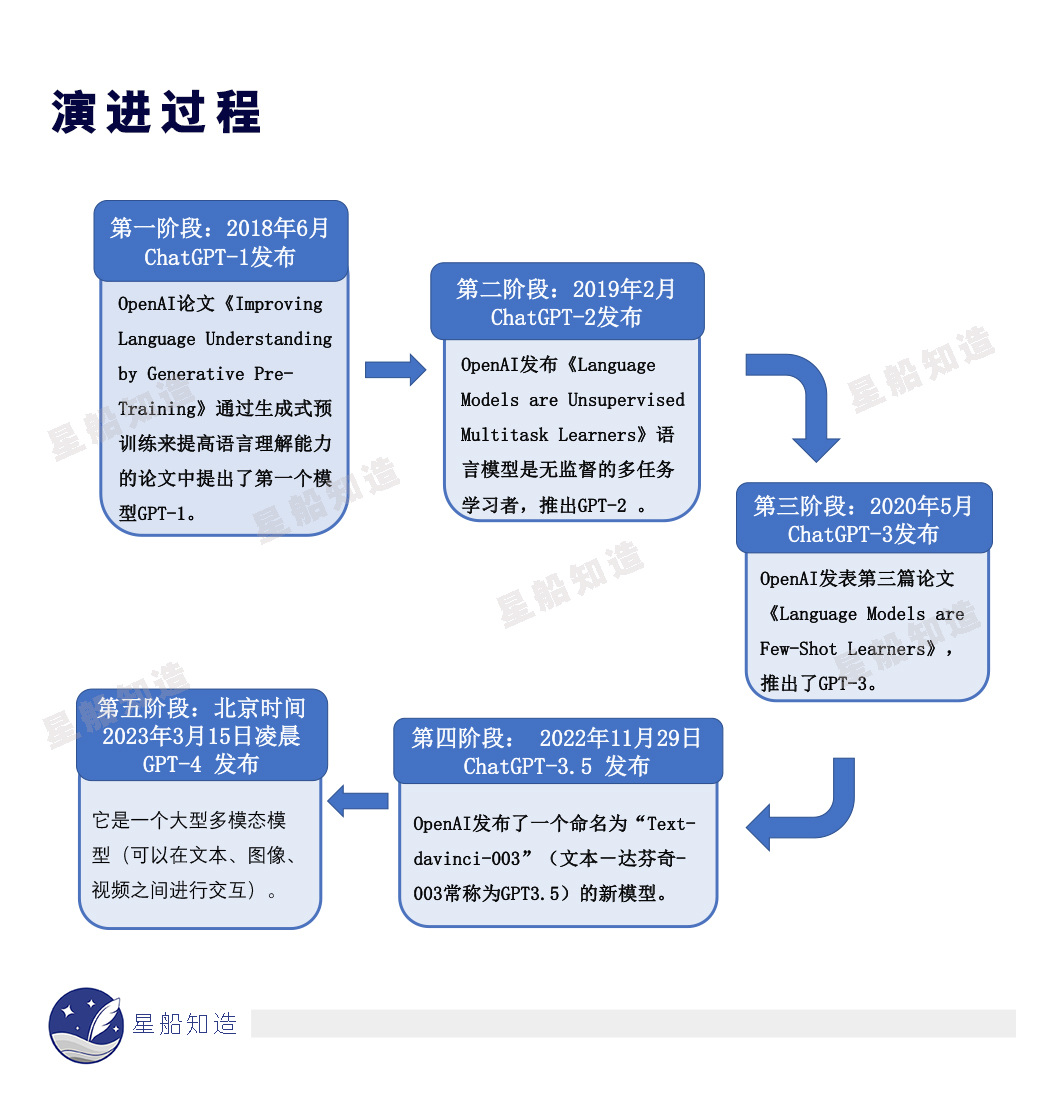
历时5年
另一些投资人则忘不掉几年前人工智能领域泡沫破裂的惨状。毕竟,从2015年开始,每一年都会被称为人工智能元年。有人说,对付泡沫的有效方法,就是用另一个泡沫取代它,也叫“嵌套式泡沫”。
回报是不确定的,商业模式是不确定的,只有风险是明确的。
资本市场最先感受到不确定带来的凉意。昆仑万维、科大讯飞、360等AI概念股自6月26日开始下挫。
SimilarWeb数据显示的ChatGPT平台访问量增速放缓的背后(1月的环比增长131.6%,到2月与3月的60%左右,再到4月接近跌破10%,5月则仅增长2.8%),是人们对其新鲜感的大幅减弱。
03 拥抱、反噬,风险和缺陷
百度集团执行副总裁、百度智能云事业群总裁沈抖说:大模型出现前的AI像氧气——有价值,但自己不会燃烧,必须找到可燃物才能发挥价值。“可燃物”,就是落地场景。
五道口和陆家嘴的咖啡馆里,人们都在聊大模型和AI。但谁也不知道该先进哪个车间。
制造业企业数智化转型的刚需仍然是降本增效。并且不会轻易交出行业数据。
星船知造在对国内服装制造企业的走访中,以及对移动机器人全场景应用者快仓等企业的沟通中,发现企业自动化及数字化布局时呈现明显的区域特点:比如,长三角和珠三角地区纺织服装企业对自动化和数字化的热情要高于内陆地区。
主要由两方面决定:一是当地的用人成本。二是企业本身的品牌定位需求。
部分企业受到淘宝等互联网公司的推动进行转型布局。
我们也从数位游戏业内人士处了解到,游戏行业在 AIGC 和元宇宙探索多年,AI一个比较大的应用落地方向是“游戏中对NPC的优化”。通过相关技术让NPC和用户进行更生动的互动,增加游戏真实感。
微软 GDC2023 上,分享了Azure OpenAI 在游戏 NPC 中应用的三大方向:游戏虚拟玩家、游戏虚拟主播、游戏 NPC 动态互动。
文章最后,加入一个使用GPT的彩蛋。大家注意避免在使用中碰到人工智障(AI,Artificial Idiot)、误联网(Internet of Error)和深度瞎学(Deep Blind Learning)。
首先是比较ChatGPT3.5和GPT4的区别?

以及别忘了GPT-4作为系列中的过渡版本,已暴露出很多缺陷,存在的缺陷与风险主要体现在以下几个方面:
首先是ChatGPT在道德和法律方面的违规行为。
ChatGPT对信息、数据来源无法进行核实、核查和验证,可能存在个人数据与商业秘密被泄露,引起窃取他人信息的道德问题和提供虚假信息两大隐患。
ChatGPT涉及的法律风险不限于以下几种:
著作权:生成的内容可能会侵犯他人的著作权。
隐私权:使用ChatGPT 可能需要提供一些个人信息,存在泄露个人隐私风险。
信息误导:生成的内容可能不准确或有误导性和歧视性。
侵权违规:ChatGPT生成的内容可能侵犯他人的合法权益,如商标权、出版权、著作权、专利权等。
商标侵权:ChatGPT 生成的图像和视频内容可能涉及商标侵权。
人身攻击:ChatGPT 生成的内容可能涉及对宗教和人身攻击,违反社会伦理道德。
偏激诽谤:使用 ChatGPT 生成的内容可能侮辱他人,可能涉及偏激、诽谤等法律问题。
其次是ChatGPT提供大量虚假信息。
ChatGPT常常一本正经的胡说八道,这是ChatGPT目前被人诟病的一个主要缺点,这就为不法分子恶意训练或误导人工智能,使其提供诈骗信息、钓鱼网站等内容,损害公民人身和财产安全创造了条件。
第三是GPT-4 引用数据同样不能实时更新。
目前GPT-4在生成性预训练中使用的数据与ChatGPT3.5的数据都是2021年底前的网络数据,不能与互联网实时联网调用数据,因此在回答2022年以后的问题时无法得到有效支撑,造成信息的误导。
第四是不善于讨论未来。
尽管GPT-4似乎可以对已经发生的事情进行推理,做出相对正确的回答,但当被要求对未来做出假设时,回答就有点答非所问,根本无法提出全新的想法。
最后,ChatGPT信息监管迫在眉睫
ChatGPT在建立语料库、生成文本时,大量使用并非公开的开源代码,或未办理许可证申请,可能会导致侵权。因此各国政府对ChatGPT必须要考虑建立相关的监管机制迫在眉睫,防止产生不良的社会影响。
参考资料:
[1]ChatGPT翻开了硬币的哪一面?北京邮电大学人工智能学院教授邓伟洪、中国信通院云大所有内容科技部副主任石霖
[2]《ChatGPT技术架构及我国人工智能未来发展策略的研究》 星船知造
[3]OpenAI官网(ChatGPT:优化对话的语言模型 (OpenAI.com))
[4]Interactive Learning from Policy-Dependent Human Feedback (MacGlashan et al. 2017)
[5]Deep Reinforcement Learning from Human Preferences (Christiano et al. 2017)
[6]ChatGPT: Optimizing Language Models for Dialogue (OpenAI 2022)
[7]Scaling Laws for Reward Model Overoptimization (Gao et al. 2022)
[8]Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback (Anthropic, 2022)
[9]《中国人工智能大模型地图研究报告》中国科学技术信息研究所、科技部新一代人工智能发展研究中心
本文基于访谈及公开资料写作,不构成任何投资建议
本文为星船知造原创内容
未经授权,禁止转载
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







