编者按:本文来自微信公众号 新智元(ID:AI_era),编辑:编辑部,创业邦经授权转载。
根据外媒《华尔街日报》消息,Meta正在加紧开发新的大语言模型,能力将完全对标GPT-4,预计将于明年推出。

消息还特别强调了,Meta新的大语言模型将比Llama 2大数倍,而且大概率还是会开源,支持免费商用。
自从年初Meta将LlaMA「不小心」泄露出来之后,到7月份Llama 2的开源发布,Meta渐渐找到了自己在这次AI浪潮中的独特位置——AI开源社区的旗帜。

人员震荡不断,模型能力有硬伤,靠开源坐回主桌
年初,在OpenAI用GPT-4引爆了科技行业之后,谷歌,微软也相继推出了自己的AI产品。
在5月份的时候,美国监管层就邀请了当时他们认为AI行业相关的头部企业CEO,开了一个圆桌会议,讨论AI技术的发展。
OpenAI,谷歌,微软,都被邀请了,甚至还包括了初创公司Anthropic,但是却没有Meta的身影。当时官方对Meta缺席的回应是:「我们只邀请在AI行业中最知名的公司。」
好事没有轮上Meta,但是麻烦却源源不断地找上门来。
先是6月初国会一封质询信直接寄到的小扎手上,措辞严厉的要求他说明3月份LlaMA泄漏事故的前因后果。

而在后来的几个月时间里,即便在Llama 2发布之后,Meta之前花重金打造的AI团队却依然在逐渐分崩离析。
在Llama 2的致谢中,提到的4位最先发起这项研究的团队,其中三位已经离职,目前仅有Edouard Grave还在Meta。
业界大牛何恺明,也将离开Meta,回归学术界。

根据最近The Information的爆料文章,Meta的AI团队,因为对于内部算力的争夺,摩擦不断,人员陆续离开。
在这样的大背景下,小扎自己应该也很清楚,Meta自己的大语言模型,也确实没有办法和业内最前沿的GPT-4沾边。
不论是在各个方向的基准测试还是从用户反馈来看,Llama 2和GPT-4的差距依然还比较大。
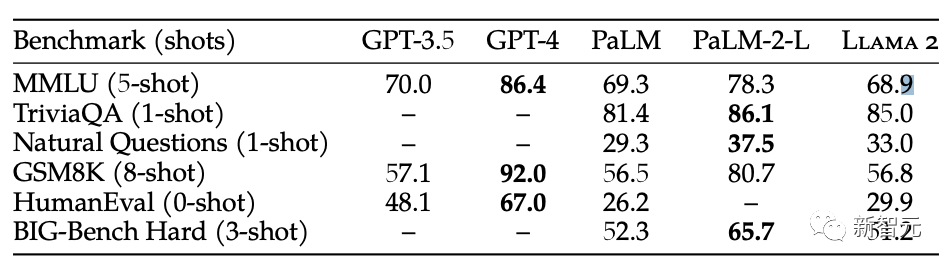 在各项基准测试中,开源的Llama 2和GPT-4还有不小差距
在各项基准测试中,开源的Llama 2和GPT-4还有不小差距
 网友的实际体验也在不断强调GPT-4比Llama 2依然突出不少
网友的实际体验也在不断强调GPT-4比Llama 2依然突出不少
于是,小扎决定让Meta直接在模型开源之路上继续一路狂奔。
也许小扎背后的逻辑是这样的:Meta模型能力一般,打不过闭源大佬,藏着掖着也没啥意义。那就索性开源让AI社区以自家模型为基础来不断迭代,扩大自己产品在业界的影响力。
而且小扎也不止一次的在公开场合表示,开源社区针对自己模型的迭代会让自己的技术团队获得启发,从而在未来开发出更有竞争力的产品。
 小扎在Fridman的播客中强调,开源能让Meta从社区中吸取灵感,而且未来Meta可能会推出闭源模型。
小扎在Fridman的播客中强调,开源能让Meta从社区中吸取灵感,而且未来Meta可能会推出闭源模型。
参见:https://lexfridman.com/mark-zuckerberg-2/
而事实也证明,Meta的这个选择确实是正确的。
虽然在算力资源和技术实力上比不上谷歌,OpenAI,但是Meta的Llama 2等开源模型对于开源社区的吸引力依然是首屈一指的。随着Llama 2慢慢成为AI开源社区的「技术底座」,Meta也在行业中找到了自己的生态位。
最明显的一个标志是,马上9月份将要召开的国会AI闭门会议之中,小扎终于成为了监管层的座上宾,和谷歌、OpenAI等行业最前沿的公司CEO一同作为代表,对于AI行业监管发出自己的声音。

而如果明年Meta推出的新模型,能够继续保持进步,获得和GPT-4持平的能力,一方面能让开源社区继续拉近与闭源巨头的差距,坐实了「开源社区与行业最先进水平差距在一年左右」的说法。
另一方面,小扎在采访中也曾透露,如果未来大模型能力进一步提升,Meta可能会推出自己的闭源模型。如果新的模型能进一步迫近行业SOTA,也许就离Meta推出自己的闭源模型不远了。
虽然Meta看起来在这波AI浪潮中已经暂时落后了,但是小扎的野心也不甘心只做一个追随者。
在「AI三巨头」Yann Lecun的指引下,Meta也正在为颠覆整个行业做着准备。
Meta的未来
所以,这个传说中能比肩GPT-4的神秘大模型之后,Meta AI未来会是什么样子?
因为目前还没有具体信息,我们也只能做一番猜测,比如从Meta AI首席科学家LeCun的态度入手。
当红炸子鸡GPT,一直是LeCun批评和鄙视的人工智能发展路线。
今年2月4日,LeCun就直白地表示,「在通往人类级别AI的道路上,大型语言模型完全是一条歪路」。

他认为这种根据概率生成自回归的大模型最多活不过5年,因为这些人工智能只是在大量的文本上训练的,它们无法理解现实世界。
所以这些模型既不会计划也不能推理,它们拥有的只是上下文学习能力。
严肃的说,这些在LLM上训练的人工智能几乎毫无「智能」可言。
而LeCun期待的,则是能够通向AGI的 「世界模型」。
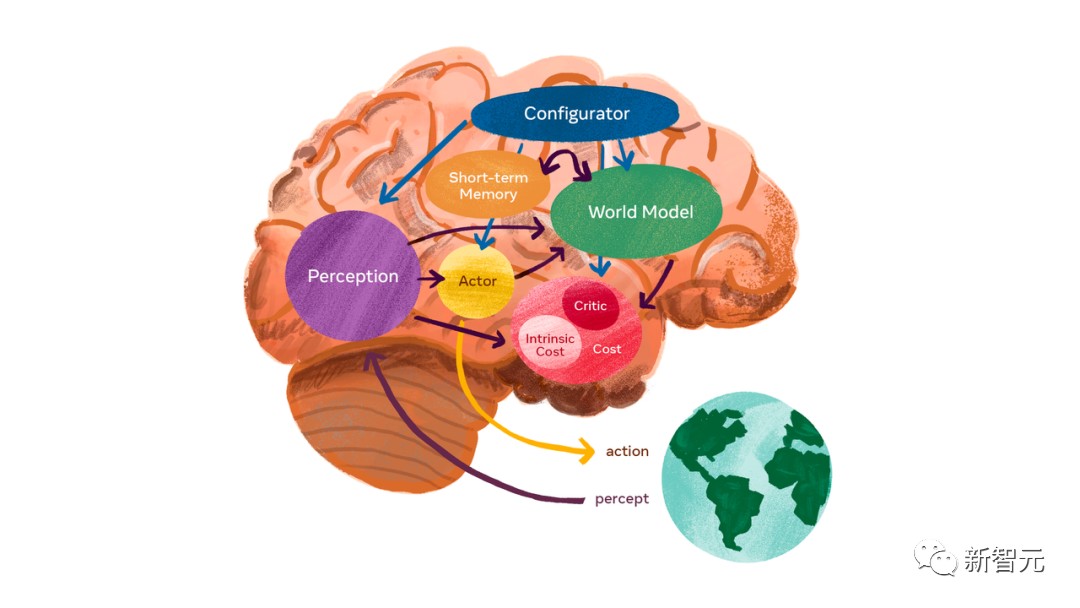
世界模型能够学习世界如何运作,更快速地进行学习,为完成复杂任务做出计划,并随时应对不熟悉的新情况。
这与需要大量预训练的LLM不同,世界模型能够像人类一样,从观察中找到规律,适应新环境、掌握新技能。
相较于OpenAI在LLM领域不断精进深耕的策略,Meta力求多样化的模型开发。
今年6月14日,Meta发布了一个「类人」的人工智能模型 I-JEPA,也是史上第一个基于LeCun世界模型愿景关键部分的AI模型。

论文地址:https://arxiv.org/abs/2301.08243
I-JEPA能够理解图像中的抽象表征,并通过监自督学习获取常识。
并且I-JEPA不需要额外的人工制作的知识作为辅助。
之后,Meta推出了Voicebox,这是一个全新的突破性语音生成系统,基于 Meta AI 提出的一种新方法——流匹配。

它可以合成六种语言的语音,执行去噪、编辑内容、转换音频风格等操作。
Meta还发布了通用的具身AI agents。
通过语言引导技能协调(LSC),机器人能够在部分预先映射的环境中,进行自由的移动、拾取。
,时长00:30
在多模态模型的开发中,Meta也与众不同。
ImageBind,第一个能够从六种不同模态绑定信息的人工智能模型。
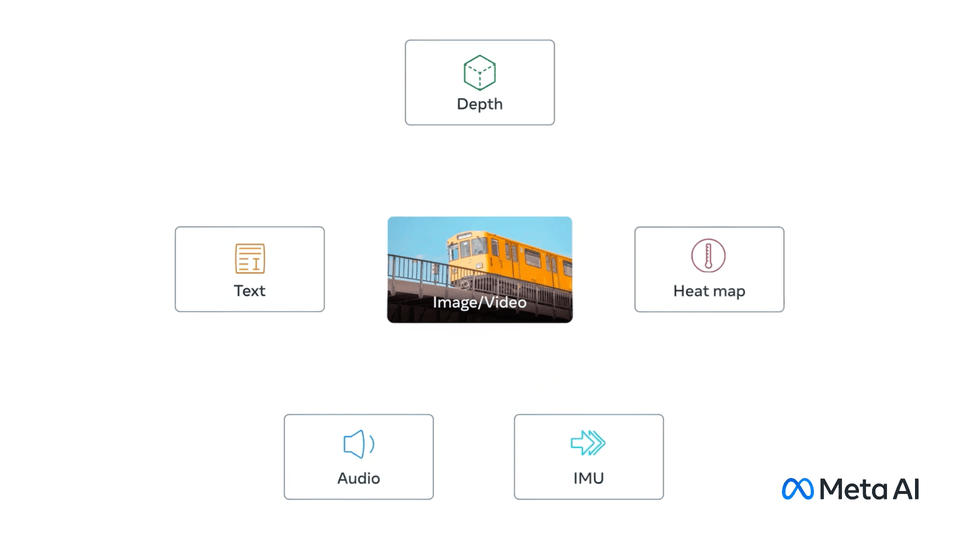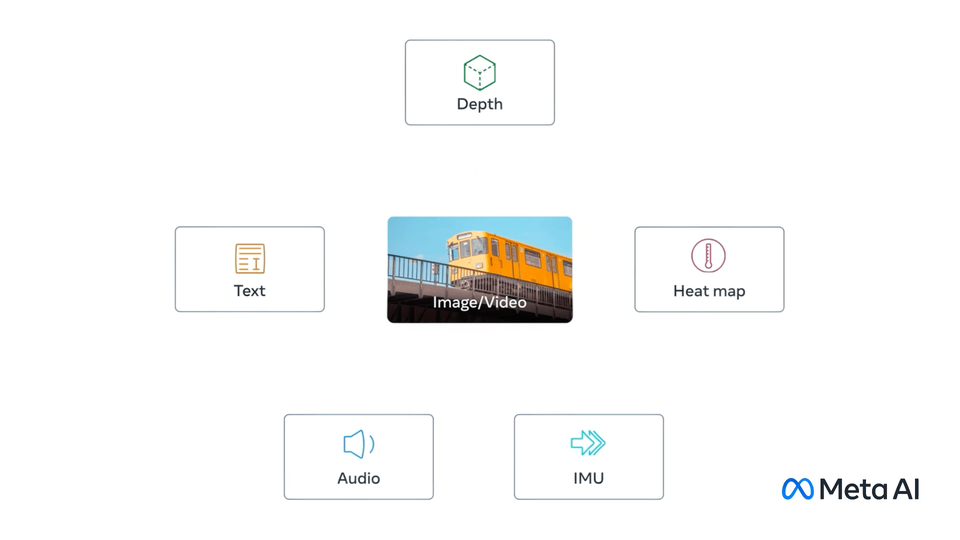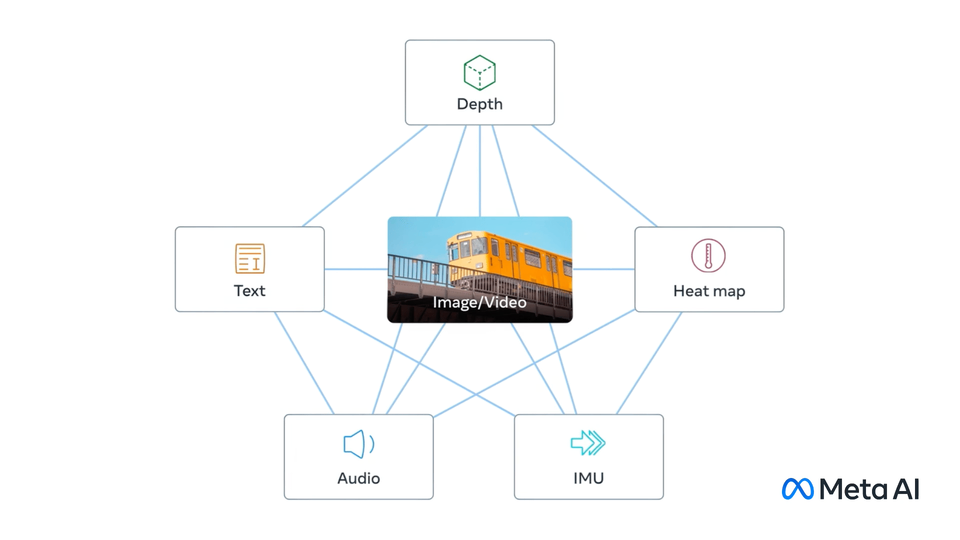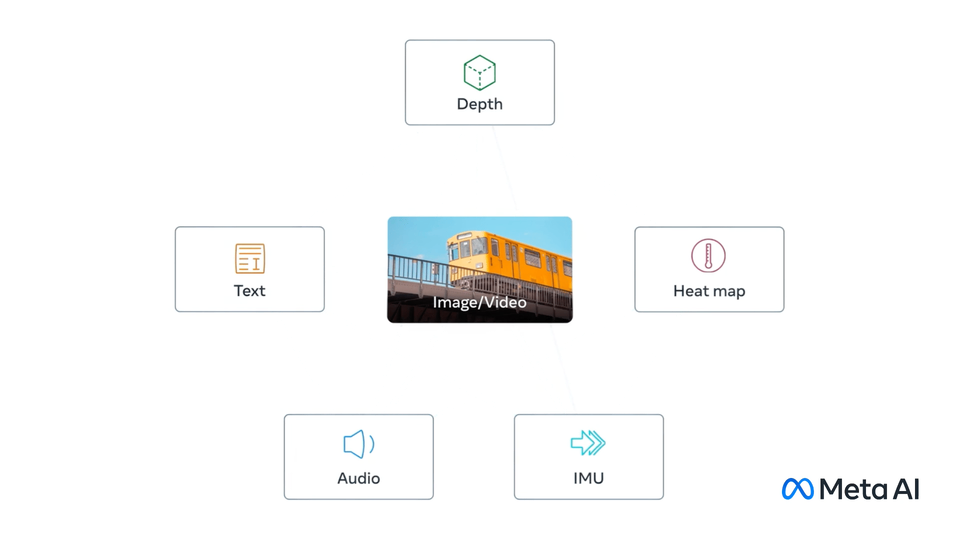
它赋予机器全面的理解能力,将照片中的物体与它们的声音、三维形状、温度以及运动方式联系起来。
而来自Meta AI和CMU_Robotics共同开发的RoboAgent,让机器人可以获得各种各样的非平凡技能,并将它们推广到数百个生活场景中。
同时,所有这些场景的数据都比该领域先前的工作少一个数量级。

对于这次爆料的模型,有网友表示,希望他们继续开放源代码。
不过也有网友表示,Meta要到2024年初才会开始训练。

但令人欣慰的是,Meta依旧释放了自己将继续坚持原有战略的信号。
参考资料:
https://www.wsj.com/tech/ai/meta-is-developing-a-new-more-powerful-ai-system-as-technology-race-escalates-decf9451?mod=followamazon
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







