2 月 16 日凌晨,OpenAI 发布了自己的首个 AI 视频生成模型 Sora。这是一个历史性的里程碑,扩散模型结合Transformer,在视觉领域实现了与大语言模型类似的突破。毫无疑问,视觉生成领域将有一次大的技术和商业革命。
国内生成式人工智能初创公司 HiDream.ai 智象未来在成立之初即立下做国内最厉害的多模态视觉大模型的目标。在成立不到一年的时间,自研的“智象视觉大模型”已成为目前全球同时支持图像和视频生成的最大模型,模型参数已超过 130 亿,实现文本、图片、视频等多模态内容的生成。
团队在研究相关技术后也进行了相应的分析,本文将带来 CTO 姚霆博士的技术解读,以及我们对于 AI 生成视频技术在影视级应用方面的思考与实践。
智象未来 CTO 对 Sora 的技术解读
作者:姚霆博士,智象未来联合创始人兼 CTO
以下出现所有视频均由 HiDream.ai 千象产品生成
在探讨视频生成技术革新之前,我更愿意去思考电影这一独特的视频艺术美学。在众多关于电影本质的观点与探讨中,最让我印象深刻是这些:
“电影是一种介于现实和梦幻之间的艺术形式。”
“电影是一种时间艺术,它捕捉了时间的流动和变化。”
“电影是一种视觉艺术,它利用图像来讲述故事和表达情感。”
从技术的角度可以对照着去解读电影/视频的本质:
它可以是介于现实和梦幻之间的一个新的世界(类似于盗梦空间的新的时空世界)

也可以是 2D 平面在时间维度的流动和变化(视频帧的序列)

还可以说从静态图像出发,依托故事和情感来驱动(静态图像加上对应的全局/局部运动)
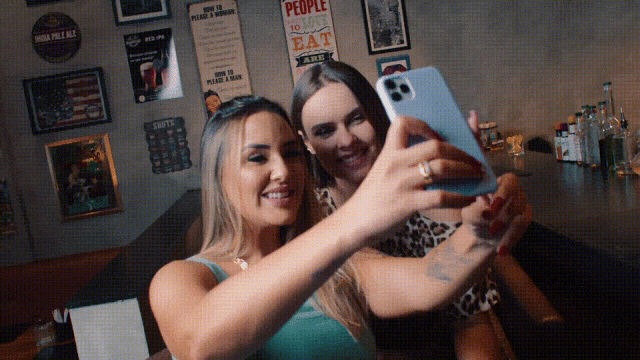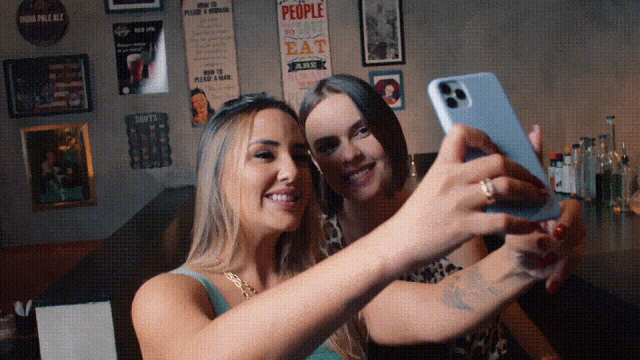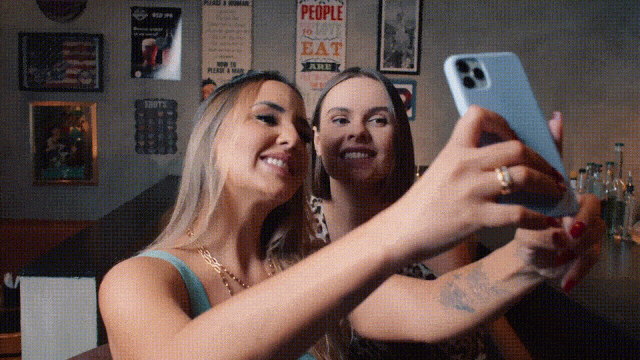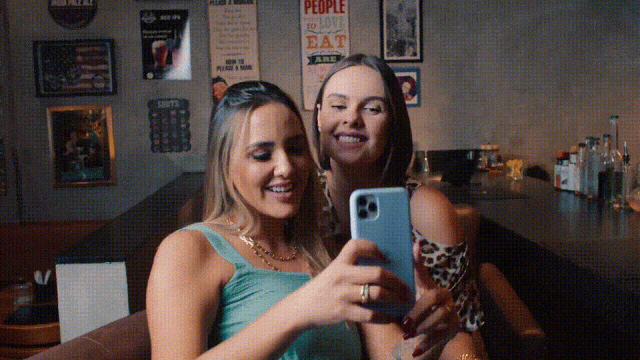
目前主流的模型框架 Diffusion model 和 Auto-regressive model,恰好对应着前两种视频本质。Video Diffusion model 往往将视频看作一个时空的网格世界,并用 3D 卷积神经网络/Transformer 来进行编码;Auto-regressive model 则将视频理解为连续帧的序列,搭配 GPT 典型的自回归模型来进行编码。Diffusion model 基于扩散模型加噪去噪的机制可以更好地结构化并生成较高质量画质的视频内容,而 Auto-regressive model 更适合长上下文语境理解,天然适配多模态对话的生成方式。

AI 生成视频,一个典型的技术流程是:利用 LLM 自动生成剧本来驱动视频,提升故事逻辑性,加入全局/局部运动的控制,实现精细的全局运镜和局部动作,最终结合图像/视频增强生成4K/8K的超高清视频。
从视频商业化路径来看,故事逻辑性、视觉可控性与画质高清是实现视频产品落地最后一公里的三大要素,也是电影这一视觉艺术在用户侧最直击内心的因素。
我们面向广大创作者推出了 AI 生成图片和视频的工具——Pixeling 千象(www.hidreamai.com,千象万相),帮助用户一站式生成精准可控的图片、视频,经过视频增强后生成的 4k 超清画质,完美展现脑中灵感。非常多用户使用千象制作完成了他们的“电影大片”,比如这位来自北京电影学院数字媒体专业的研一学生,用千象制作了《Savague Daughter》这部北欧童话短片,通过精美的画面展现壮丽魔幻的风景,带领观众攀登高山、穿越怒海、深入龙巢、翱翔天空;展现有些女孩生来即代表智慧与勇敢并存的化身。
接下来再谈谈最近当红的Sora,很多人问我怎么看,我只能说是平面世界看(一个手机屏幕),甚至于还打着灯光看(因为是在北京时间半夜发布),这也对应着我的第一个观点:
01Sora是一个 world simulator,是 2D 的平面世界在 1D 时间维度上的流动与变化。
实际上,我们真正的世界是一个 3D 的立体世界(2D 的平面世界+ 1D 深度),再叠加 1D 时间维度才是一个 4D 原生的世界模型。
从这个角度去看,Sora 可以说是 4D 原生世界的一个低阶版本(去除了 1D 深度),当然也有很多人猜测Sora训练数据里包含了3D渲染数据,通过这样一种 data-driven 的方式去模拟视频中的 3D 视觉效果,这也可称之为是对世界模型的模拟。
02Sora 的出现也会促使技术人员去重新思考视频生成的设计逻辑。
已有的 Video Diffusion model 会有两种设计理念:一种是 image-to-video,即先训练一个文生图模型,然后再训练图生成视频模型;另一种是 joint-image-video,即文生图、文生视频的联合训练。而 Sora 的底层逻辑是 world simulator(2D 的平面世界+ 1D 时间维度),所以采取了 video-native 的设计理念,即将整个 2D 的平面世界+ 1D 时间维度编码为时空模块(space-time patches),这样图像作为单帧视频很自然的加入模型的训练,同时 Sora 模型训练完成后可以无缝切换为图像生成模型。
03为什么是 OpenAI 实现了 Sora?
在我看来 Sora 是 OpenAI 集成自己语言(GPT)、视觉理解(GPT4-V)和图像生成(DALL-E)多种能力的一个出口。视频作为一门更为灵动、更具表现力的艺术美学,有着独特的时空魅力,成为多模态内容展现的一个绝佳载体。
智象未来,追赶同时打造自己的差异化
总结来说,Sora 的视频生成技术架构本身并未有大的创新,还是Diffusion Transformer,这说明视频 AIGC 技术架构尚未收敛。目前,智象未来团队已经完成图像 Diffusion Transformer 架构 130 亿参数规模的训练,计划二月份推出重大迭代的图像基础模型(V3.0);同时,我们也在积极将这一技术迁移到视频生成领域,预计三月底实现视频基础模型大幅升级(V2.0)。
智象未来的独特之处在于我们对视频生成过程中的关键要素——视觉故事性、内容确定性、超高清画质(4K/8K)以及全局和局部的可控性——的专注。这些特性正是影视行业的核心需求,也是 Sora 乃至行业目前尚未实现的。我们预计在三月底的视频模型将在一致性、生成时长和连贯性等方面带来显著提升,为用户带来更加丝滑、顺畅的视频生成体验!
本文作者
姚霆,联合创始人兼 CTO
姚霆博士是计算机视觉和多媒体领域的全球知名学者,他发表的论文被引用1.5万余次,先后10余次获得国际学术竞赛冠军,设计了视频分析领域标准的3D卷积神经网络Pseudo-3D Network,构建的业界首个大规模视频文本数据集MSR-VTT被全球四百余研究机构的学者下载使用,并研发了多款全球数百万日活用户的商业产品,他曾任京东科技算法科学家和微软研究院研究员。
姚博士获评2022 年度中国图象图形学学会科技进步奖一等奖,2022 IEEE ICME Multimedia Star Innovator,2019 ACM SIGMM Rising Star,2019 IEEE TCMC Rising Star,并在多个国际学术组织中担任重要职位。




