编者按:本文来自微信公众号 腾讯科技(ID:qqtech),作者:四木相对论,编辑:郑可君、郝博阳,创业邦经授权转载。
过去12个月,几乎所有的大模型六小虎都遇到过“不得不选”的时刻。只不过,2024年上半年他们还在选“该走哪条路”,下半年则只能考虑“还剩哪条路可以走”了。(编者注:大模型六小虎为国内六家在大模型开发上较为领先的创业公司统称,包括智谱、MiniMax、月之暗面、百川、零一万物和阶跃星辰。)
一位在2024年投进六小虎的投资人告诉「四木相对论」,2024年上半年,大多数小虎的融资还处于烈火烹油的状态。
他举了一个例子,以示他们在盛极时刻的状态:当时,以Kimi为代表的明星公司不仅不开放全部尽调,还有老股东计划对一些希望入局的小股东们设置投资机制,自己从中赚取新的管理费。
但到了下半年,在投资市场和AI行业,包括六小虎在内的AI初创公司们,口碑开始急转直下。“现在除了国资,基本没有什么潜在买家。”上述投资人表示。
此外,「四木相对论」还了解到,有一、两家小虎希望长期寻找国际化资本的支持,但没有拿到结果。
除了融资难,业务更难。
2024年上半年,六小虎们还在考虑做To C还是To B,聚焦国内市场还是进军全球市场。到了下半年,大家发现国内的C端用户忠诚度不高,B端钱又很难赚,六小虎中至少有三家认真考虑过出海。
但是,在月之暗面阶段性收缩出海业务之后,近期又有一家明星大模型公司对北美团队进行了裁撤。MiniMax的海外拳头产品Talkie,12月中旬也在美区 App Store 中消失。
不能说大模型公司这一年没有进步,但却和一年前的市场预期相去甚远。
这一困局不仅限于中国的六小虎,无论是激进的国内大厂,还是海外AI公司,都经历了曲折的一年。
现状:巨头“搅局”,赚钱的业务寥寥
首先,以通用助手为代表的To C模式,已经不是初创企业玩得起的“乐园”。
“接下来的目标,是追平豆包目前的用户数量。”一位头部六小虎的业务负责人告诉我们,这是这家公司近期经过业务复盘,对通用助手产品提出的预期。
临近年底,多家公司开始复盘。
一位接近Kimi的投资人表示,它2024年原本的目标是日活1000万,现在完成了1/3左右。
1000万,恰好接近豆包APP近期的日活。
在内测时,豆包还叫"Grace",在Kimi、文心一言、通义千问、智谱清言甚至海螺问问(现在的海螺AI)都推出后,才在2023年9月姗姗来迟。
但一年之后,综合AI产品榜、量子位智库等渠道的数据,豆包在2024年11月的月活已经接近6000万,日活超过900万,是国内通用助手的断层第一。
在我们近期密切交流的多位创业者和投资人朋友中,大多数人认为豆包App之所以异军突起,最大优势是对流量渠道的掌控。
根据移动营销平台AppGrowing数据,2024年以来(截止11月15日),Kimi、豆包、星野等国内十款大模型产品,合计投放超625万条广告,投放金额达15亿元。

这些在各个渠道被火热传播的投放金额,被多家“主角”质疑数据有所夸大。
但至少对掌握流量渠道的大厂来说,投放金额的确用不了这么多。大厂内部的业务投放自家的渠道,往往会采用特殊的结算标准,“有时候内部部门会分得一部分流量,也可以用其他内部资源兑换。”有大厂AI从业者告诉我们。
这是初创公司无法拥有的福利。
一家在2024年获得巨头投资,估值超1亿美金的AI明星初创公司曾对「四木相对论」表示,由于自己主攻的领域和某大公司重注的方向基本重合,所以在被该大厂掌控的流量渠道上,自己无法进行投放。
Kimi也不例外。不久前曾有媒体报道,年初在抖音、B站等内容APP上刷屏并获取大量用户的Kimi,下半年在抖音上被限制投放,不得不转战快手等平台。
据“AI新榜”公众号统计,截至10月29日,Kimi在过去三个月内的广告投放总数已经超过2500条。其中,在快手平台上投放的内容超过2100条,几乎占据总投放量的84%。
还有一些没能在热钱涌动时完成融资的创业公司,负担不起日渐增长的流量成本,只能转型。
有家2024年成立的AI教育公司CEO告诉我们,自己的早期产品定价在20元,但现在投放一个人至少需要25元,“我们根本算不过来账”。
其次,To C模式之外,大厂的身影同样在大模型的To B市场掠食。
海外,大模型公司卖API是个还不错的生意。OpenAI预计2024年将依靠API赚得5亿美元,占总营收的15%。据CNBC报道,Anthropic对API的依赖更大,预计总营收的60%~75%将来自第三方调用API。
在国内,提供大模型API,愈发变成模型厂商抢占市场的方式,未被寄予丰厚的利润预期。
年中由DeepSeek和字节率先掀起的降价潮,限制了API的价格空间。
5月,DeepSeek推出DeepSeek-V2 ,价格直接“杀”到了每百万输入Tokens1元,每百万输出Tokens2元。
同样是在5月,字节跳动把豆包通用模型pro-32k版的推理输入价格定为0.0008元/千tokens,比行业均价低99.3%。
面对价格攻势,竞争对手只能快速应对。阿里将通义千问主力模型的价格下调97%;百度宣布文心两款模型免费。
「四木相对论」了解到,2024年初,字节内部就定下了要成为LLM调用市场第一的目标。其中,企业客户的占比要接近一半。为此,火山引擎还组建了算法和服务数十人团队,帮助客户做咨询、测试Prompt,消耗量大的“优质客户”有机会获得更多优惠。
一位大厂的大模型销售告诉我们,现在一个日Token消耗超过二十亿的客户,用豆包API每月花费的成本只需要小几千。但在其他公司,这样的模式不一定被支持。
到了年末,字节已经在检索、对话、文娱、游戏、客服等领域,收获了不少公有云客户。
第三,仅剩的商业模式,还有服务大B客户的私有化部署。
这个领域,目前基本是国企和讯飞、百度的地盘。

智谱在很长时间里,是唯一从中刷到存在感的初创公司。到了2024年下半年,百川和零一,也出现了个位数的公开中标信息。
对比2023年年初大模型1000万的部署价格,现在一些纯软件、小几百万的单子,算上人力成本和服务周期,很可能导致AI公司“做一单亏一单”。但即便如此,在非招投标渠道中,各AI公司的私有化部署业务已开始白热化抢夺。
一家在2024年下半年才加入大B市场的六小虎,曾尝试按市场价沟通客户,但后续遇到另一家老牌“四小龙”故意压低价格,客户选择了低价的一方。
最后一点,笃信公有云的巨头也开始谋划私有化市场。
前不久,火山引擎总裁谭待表示,虽然他更看好在公有云上使用大模型,但接下来混合模式还会持续存在。
2024年下半年,火山引擎开始频繁出现在招投标信息中。字节最近主推的AI应用开发平台「HiAgent」,由于主攻企业场景,也会搭载豆包的私有化部署版本。
事实上,虽然很多人是在年底举办的火山「原动力大会」上第一次听到HiAgent——此前更被熟知的是更偏开发者属性的Coze/扣子,但HiAgent至少已经低调出现半年之久。
当时——也就是2024年年中,火山的不少内部员工还未意识到字节也希望提供一些私有化部署方案。有AI公司的员工反馈,之后的几个月,字节的销售开始对外许诺可以免费帮企业部署、微调。
面对巨头的全面进攻,初创公司的业务方向变得飘忽不定。
10月,六小虎中有不少放弃预训练的消息传出。虽然,继续盲目提升参数量可能会导致模型效果的提升与投入不成正比。但这一动作,还是会让它们动辄几十亿美金的估值被打上问号。
有两位投资人向我们透露,一家估值不在前三、且确定转型垂类领域的小虎,甚至已把用作预训练的卡卖掉了。
全行业:Killer App未出现,技术急需新范式
反差的地方在于,已经吸金数十亿的AI通用助手,并不是所有人心中的Killer App。
前不久「智能涌现」曾报道,即便豆包用户数断层第一,但字节高层认为它只是产品的中间态,另一款App——即梦的优先级被提升。
我们观察到,即梦在持续尝试将AI生成的内容,转化为App中的Feeds流。这个细节折射出,虽然即梦的关注度远弱于豆包,但它或许更加AI Native。
更多AI Native应用,还处在跑出来的过程中。
2023年3月,开源项目 AutoGPT 的爆火,让能够独立完成人类任务的Agent走到更多人面前。2023年底,OpenAI推出GPTs之后,国内大厂们开始争相推出如 Coze/扣子、百度文心智能体平台等一系列Agent构建平台。
但从实际表现来看,无论是订机票、还是买咖啡,Agent依旧难被顺滑使用。比如,采用了Agent的麦当劳AI点单系统,已经因为经常错误下单被关停了。加拿大航空的Agent——咨询和理赔机器人也因为随意给出并未被授权的优惠券被下线。

(麦当劳AI点单系统错误地给顾客添加了数百美元的鸡块)
Agent进展缓慢的根本原因还是模型能力不足。
在12月的火山FORCE大会上,火山引擎总裁谭待表示,Agent落地的核心还是技术要好;智谱2024年也在持续招募技术人才,目的之一是通过提升模型能力,让Agent的效果更好。
整个2024年,大模型技术的最大变量是通向AGI之路的法则——Scaling Law正在失效。
OpenAI在2020年发布的论文指出,模型的性能会随着模型参数量、训练数据规模、训练计算资源的增加而呈现线性增长,这是第一代Scaling Law的核心观点。
然而,Llama-3.1-405B 这样参数量的模型,在几乎用尽了所有公开数据集进行训练后,实际效果并不理想——很多评测场景的结果,它与自家70B的模型相差不大;OpenAI在GPT-4后,也未在2024年推出通用能力明显提升的基础大模型。它的GPT-5,被《华尔街日报》曝出由于高质量数据不足等原因,效果远不达预期。
“GPT-5已至少完成2轮训练,每次长达数月,但是每次训练后都遇到新问题。”《华尔街日报》援引知情人士称。

(华尔街日报报道)
预训练的规模秘诀失效,OpenAI和Anthropic给出的解法,是通过强化学习(RL)提升模型推理能力。
2024年9月中,OpenAI上线了首个推理模型--o1。12月底,进阶版推理模型o3上线。它展现出大模型在科学、编码、数学等领域解决复杂问题的能力,引来各家追随。
11月,也就是OpenAI的 o1 发布两个月后,国内至少有近10个团队在复现o1。

但o1、o3这样的推理模型,也存在争议。
“测了一圈国内的类o1模型,效果都差强人意。”一位从事模型研究的算法工程师告诉「四木相对论」,“阿里的QwQ效果能好一点。如果o1是100分,QwQ能达到60-70分。”
另一种声音是质疑o1、o3的“应用场景太狭窄”。在数学、代码之外,它适配的场景并不多。如果再算上成本,落地前景并不明朗。
2025:模型层收敛,AI应用起飞?
在这个技术迷茫期,国内的大模型公司开始悄然分野。
现在训练一个性能接近Claude3.5 Sonnet或GPT-4o的模型,价格并非高不可攀。
DeepSeek 最新发布的V3,训练成本是557.6万美元。
但它在技术报告中特地表明,这个价格只是正式训练的成本,不包括之前的研究和算法、架构、数据的试验成本。
如果想真正突破到下一代模型,大模型公司要付出更高的“试错代价”。
OpenAI的经历侧面证明了这一点。
早在2022年,它大火之前,一年的花费是5.4 亿美元。而到了2024年,The Information报道,OpenAI的成本恐怕高达85亿美元。这里面,训练和推理成本占了70亿美元,人员成本15亿美元。
筛选人才和算力这两个要素,2025年坚持训练底层大模型的国内公司,恐怕只会剩下四、五家。
根据科技咨询公司Omdia的报道,2024年采购GPU最多的国内大厂是字节和腾讯。我们了解到,从2023年起,字节内部就在“不惜一切代价”囤卡。2024年,它依旧在抢夺GPU和内含GPU的整机。
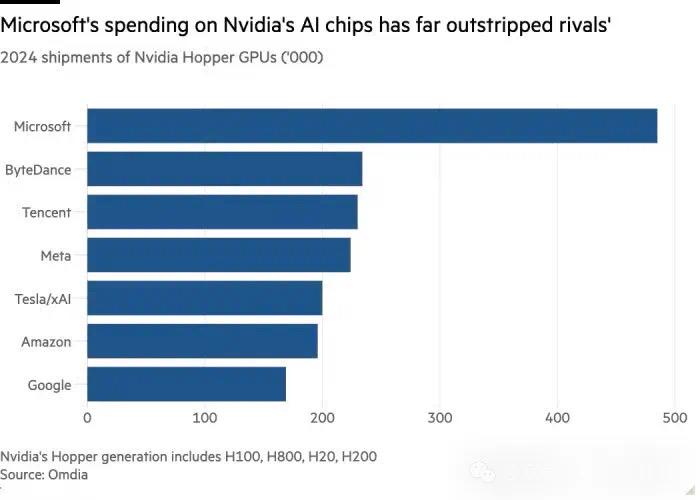
(科技咨询公司Omdia估计,2024年买卡最多的国内公司是字节和腾讯)
高端人才的密度,是提升模型效果的又一个砝码。
一位头部大模型公司高管曾对我们评价,字节豆包大模型的效果,是在高价挖来原通义千问技术负责人周畅后,才有明显起色。
和张一鸣的动作一致,最近,科技圈的另一位大佬雷军也开始亲自下场挖人。12月底,DeepSeek成员罗福莉被曝出即将加入小米大模型团队。
「四木相对论」还了解到,由于雷军的顺为资本投资了智谱、月之暗面、百川智能、MiniMax等公司。雷军在招揽人才期间,也亲自接触了六小虎的高管。
“但小米开出的Offer不一定有吸引力。”一位AI投资人表示,虽然小米在努力挖人,但算上算力资源和品牌知名度,还是难和“抢人大户”字节相比。
六小虎中,被认为会坚定发力模型层的公司是智谱和阶跃。它们在12月分别公布了数亿元的大额融资。
还有一个出人意料的面孔出现在了资本市场。多方消息称,DeepSeek数月前就在推进独立融资。

(DeepSeek于12月26日发布通用模型DeepSeek-V3,图源DeepSeek官网)
抢人、抢卡、“抢钱”,模型层的选手们,都在为2025年储备粮草。
经过一年的快速狂飙,基础大模型的早期套利空间宣告结束。
剩下的创业者,大概率会主攻AI应用。2024年底,十余家早期投资机构告诉我们,2025年会重点关注AI应用。
这一趋势已初现端倪。
近期最快拿下大额融资的项目,几乎都是创始团队为大公司高管或六小虎联创的AI应用。这类项目团队背景闪亮,融资周期极短,一般会由三、四家知名美元基金一起抢定首轮融资,估值迅速飙升至亿元级别。
最近的例子,就是追觅前中国区执行总裁郭人杰的消费机器人创业项目。我们还了解到,一些大厂和创业公司的高P近期也在筹备创业,正在初步接触投资人。
至于小而美的AI应用团队,虽无法斩获巨额融资,但有更高概率收获50万美金左右的小额投资支票。这些团队的员工一般只有个位数。他们会基于大模型,做出AI内容创作、AI健康监测、AI小游戏等精巧的功能/应用。50万美金至150万美金的投资,足够支撑他们跑出第一、二个版本的产品,获得用户和一部分收入。
这些迹象表明,到了2025年,AI应用创业者的融资环境或许会宽松许多。
但另一个问题是,不论是明星创业者的AI Coding、消费机器人项目,还是开发者小团队的AI创作应用、健康监测,似乎都和想象中Killer APP的样子有些距离。
“团队背景很重要,数据很重要,增长很重要。”不止一位AI投资人如此总结自己对AI应用的投资标准。
这个和移动互联时代如出一辙的标准,似乎说明对Killer App的思考已经搁置。
2025年会告诉我们答案吗?
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







